오라클 함수기반 인덱스(Function Based Indexes)
EMP 테이블의 ename 컬럼에 인덱스가 생성되어 있을 때 다음과 같은 경우 WHERE 절에 SQL함수(SQL Function)가 사용되어 경우 인덱스 컬럼의 원래 모습에 변형이 생겼다고 이야기 하고 이 경우 원래의 ename 인덱스를 경유하지 못하고 원본 데이터에서 전체 테이블을 FULL SCAN 하면서 일일이 원하는 데이터를 찾게 됩니다.
SELECT EMPNO, ENAME FROM EMP WHERE SUBSTR(ENAME, 0, 1) = 'S';
<실행결과>
| EMPNO | ENAME |
1 | 7788 | SCOTT |
2 | 7369 | SMITH |
실습용 테이블 EMP에는 고작 14건의 데이터 밖에 없어서 데이터를 추출하기 위해 어떤 경로를 경유하는지 별 의미는 없지만 대용량의 테이블에서는 상황이 달라 집니다. 쿼리하나 잘못 사용하면 전체 시스템이 마비 될 수도 있으니 말입니다.
위 쿼리문의 실행계획을 살펴보면 전체 EMP 테이블의 레코드를 하나씩 처음부터 읽으면서 조건에 맞는 데이터를 찾고 있는것을 확인 할 수 있습니다. 대용량 테이블에서는 이런식으로 데이터를 추출하면 2박3일이 걸릴수도 있다는 점 명심하세요. SQL 튜닝의 대부분은 인덱스를 잘 다루는 것임에 명심하시고 SQL을 처음 배울 때 부터 이런 부분에 대해 신경을 쓴다면 멋진 SQL 개발자가 될 것 입니다.

실행계획의 단계 단계를 STEP 이라고 하며 각 STEP별로 그 단계에서 어떤 오퍼레이션이 어떻게 수행되었고, 단계에서 반환 할 예상 행의 수(CARDINALITY),이를 위해 얼마만큼의 비용(COST)이 들었는지가 표시됩니다. 더 높은 카디널리티는 더 많은 행을 가져올 것이고 더 많은 작업을 하므로 쿼리가 더 오래 걸리고 따라서 대체로 비용(COST)은 더 높습니다 .
OPTIONS의 FULL은 EMP 테이블을 전체 처음부터 끝까지 한 행씩 읽었다는 뜻 입니다. 이를 FULL TABLE SCAN 이라고 합니다. 대용량 테이블인 경우 이런 FULL SCAN은 대체로 성능상 좋지 않습니다. 아래 테이블 레벨의 Filter Predicates는 한 행씩 데이터를 읽으면서 ename의 첫번째가 ‘S’ 인지를 검사하는 필터링 조건 입니다. 현재 EMP 테이블은 14건 밖에 없어서 성능 차이를 못느끼지만 시스템에 따라 차이가 있지만 데이터가 수천만건, 수억건 이상인 경우 위 쿼리문은 악성 쿼리가 될 확률이 많습니다.
위 쿼리문을 수정하지 않고 쿼리 성능을 개선할 방법은 없을까요?
당연히 있습니다. 바로 이 장에서 학습할 함수기반 인덱스function based indexes 입니다. 함수기반 인덱스는 오라클 8i 이후 도입되었으며 SQL 문장의 WHERE 절에 SQL함수(SQL Function)가 사용되는 경우 인덱스 컬럼에 변형이 생겨 인덱스를 사용하지 못하게 되는데 이를 해결하고자 함수 결과 자체를 통으로 인덱스를 만든 것 입니다. 그래서 함수결과가 어떠한 것을 찾을 때 인덱스를 이용하게 되고 성능상 이점이 있는 것 입니다.
함수기반 인덱스는 칼럼에 대해 SQL함수, 표현식 등에 인덱스를 생성하며 내부적으로 비트맵 인덱스bitmap indexes로 생성됩니다.
작성방법은 기본 인덱스 생성 방법과 동일하며, 단지 테이블명 다음에 함수나 표현식이 들어 옵니다.
[기본형식]
CREATE INDEX index_name ON table_name (function or expression) |
앞에서 작성한 쿼리문을 변경하지 않고 함수기반 인덱스를 이용하여 다시 작성하는 실습을 해보고 쿼리문을 변경하여 보다 효율적인 쿼리문을 만들어 보겠습니다. 또한 생성한 함수기반 인덱스를 딕셔너리 뷰에서 확인해 보겠습니다.
실습
함수기반 인덱스를 생성 합니다.
SUBSTR(ENAME, 0, 1) 구문에 대해 함수기반 인덱스를 생성하세요. |
CREATE INDEX IDX_SUBSTR_ENAME ON EMP(SUBSTR(ENAME, 0, 1) );
[실행결과]
Index IDX_SUBSTR_ENAME이(가) 생성되었습니다.
앞에서 작성한 SELECT 쿼리문을 다시 실행하고 실행계획을 확인하여 보겠습니다.
SUBSTR(ENAME, 0, 1) 구문에 대해 함수기반 인덱스를 생성하세요. |
SELECT EMPNO, ENAME FROM EMP WHERE SUBSTR(ENAME, 0, 1) = 'S';
[실행결과]
| EMPNO | ENAME |
1 | 7788 | SCOTT |
2 | 7369 | SMITH |
[실행계획]

실행계획이 변경 되었습니다. 실행계획을 읽는 방법은 가장 먼저 어디부터 읽어야 할지를 찾아야 하는데, 위에서 아래로 오면서 오른쪽으로 가장 많이 들여쓰기 된 부분부터 한단계씩 상위 단계로 읽는 것입니다. 동일한 들여쓰기가 되어 있는 단계가 있다면 위 단계부터 읽으면 됩니다.
위 실행 계획의 단계는 TABLE ACCESS, INDEX 두개의 오퍼레이션을 가지는 2가지 단계 입니다. INDEX가 오른쪽으로 가장 많이 들여쓰기 되어 있으므로 먼저 해석을 합니다.
1. IDX_SUBSTR_ENAME 인덱스를 읽어 조건 SUBSTR(ENAME, 0, 1) =’S’을 만족하는 행에 처음 ‘S’가 나오는 행에 RANDOM ACCESS 하여 인덱스의 일정 범위를 읽는 부분 범위 스캔(RANGE SCAN)을 하여 ‘S’인 레코드를 찾습니다.
2. SELECT 리스트에 empno, ename이 있으므로 이를 추출하기 위해 인덱스에서 찾은 데이터의 ROWID를 이용하여 EMP 원본 테이블에 접근하여 empno, ename을 추출 합니다.
다음 그림을 참조하세요.
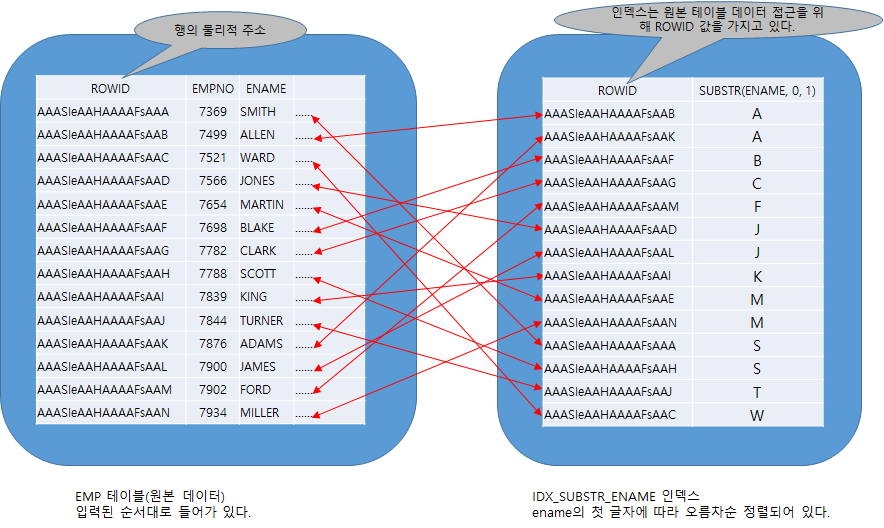
[그림 12.2 함수기반 인덱스]
실습
앞에서 WHERE절에 SUBSTR(ENAME, 0, 1)을 사용한 쿼리문을 변형하여 함수기반 인덱스를 사용하지 않고도 ename 컬럼의 인덱스를 이용하는 효율적인 쿼리문으로 바꾸어 보겠습니다.
SUBSTR(ENAME, 0, 1)을 작성한 쿼리문을 LIKE구를 이용하여 다시 작성하세요. |
SELECT EMPNO, ENAME FROM EMP WHERE ENAME LIKE 'S%';
[실행결과]
| EMPNO | ENAME |
1 | 7788 | SCOTT |
2 | 7369 | SMITH |
[실행계획]

ename 컬럼에 생성된 인덱스 idx_emp_ename 인덱스를 경유하여 데이터를 추출했습니다.
WHERE절의 컬럼에 함수를 사용하게 되면 인덱스를 사용하지 못한다는 것을 반드시 명심해 주세요. 컬럼에 변형을 가하기 보다는 컬럼 오른쪽에 문자나 숫자 상수가 있다면 거기에 함수를 사용해야 합니다. 또한 위 쿼리문처럼 LIKE등을 이용하여 컬럼에 함수를 사용하지 않을 수도 있습니다.
실행계획에서 Access Predicates는 인덱스에 접근(RANDOM ACCESS)할 때 ename이 ‘S’로 시작하는 첫번째 것을 찾아서 접근했다는 것인데, 인덱스에서 노드를 탐색하는 시작 및 중지 조건을 나타 냅니다. Filter Predicates는 인덱스에서 데이터 순회중에만 적용되며, 처음 읽은 건 다음부터 한 행씩 읽으면서 이름이 ‘S’로 시작되는 것을 필터링 했다는 것을 나타냅니다.
실습
생성한 함수기반 인덱스를 딕셔너리 뷰에서 확인 합니다.
USER_INDEXES 뷰는 사용자가 생성한 인덱스 정보를 제공하는데 생성한 함수기반 인덱스는 index_type 컬럼의 값이 “FUNCTION-BASED NORMAL”로 설정되어 있습니다.
앞에서 생성한 함수기반 인덱스를 USER_INDEXES 딕셔너리 뷰에서 확인하세요. |
SELECT INDEX_NAME, INDEX_TYPE FROM USER_INDEXES
WHERE INDEX_TYPE LIKE 'FUNCTION-BASED%';
[실행결과]
| INDEX_NAME | INDEX_TYPE |
1 | IDX_EMP_JOB_SAL | FUNCTION-BASED NORMAL |
2 | IDX_SUBSTR_ENAME | FUNCTION-BASED NORMAL |
위에서 생성한 IDX_SUBSTR_ENAME 인덱스 이외 IDX_EMP_JON_SAL 인덱스도 조회되는 이유는 인덱스를 생성할 때 내림차순(DESC) 인덱스로 생성하면 함수기반 인덱스로 만들어 지기 때문 입니다. USER_INDEXES 뷰에서는 함수 기반 인덱스가 어떤 컬럼을 기준으로 어떤 형태로 만들어 졌는지를 확인하기는 어렵습니다.
USER_IND_COLUMNS 뷰는 사용자가 생성한 인덱스 컬럼 정보를 제공하는데 생성한 함수기반 인덱스는column_name 컬럼의 값이 “SYS_NCXXXXX$”로 설정되어 있습니다.
앞에서 생성한 함수기반 인덱스를 USER_IND_COLUMNS 딕셔너리 뷰에서 확인하세요. |
SELECT INDEX_NAME, COLUMN_NAME FROM USER_IND_COLUMNS
WHERE TABLE_NAME = 'EMP';
[실행결과]
| INDEX_NAME | COLUMN_TYPE |
1 | PK_EMP | EMPNO |
…... | …... | |
6 | IDX_EMP_JOB_SAL | SYS_NC00009$ |
7 | IDX_SUBSTR_ENAME | SYS_NC00010$ |
실습하는 독자들 마다 인덱스 생성한 것에 따라 건수는 다를수 있지만 함수기반 인덱스는 SYS_NCXXXXX$ 형태로 되어 있는 것을 확인할 수 있습니다. USER_IND_COLUMNS 뷰에서도 함수 기반 인덱스가 어떤 컬럼을 기준으로 어떤 형태로 만들어 졌는지를 확인하기는 어렵습니다.
USER_IND_EXPRESSIONS 뷰는 사용자가 생성한 함수기반 인덱스 정보를 제공 합니다. 함수기반 인덱스에 관한 정보를 확인하기 위해서는 USER_IND_EXPRESSIONS 뷰를 조회하는 것이 효율적 입니다.
앞에서 생성한 함수기반 인덱스를 USER_IND_EXPRESSIONS 딕셔너리 뷰에서 확인하세요. |
SELECT INDEX_NAME, COLUMN_EXPRESSION, COLUMN_POSITION
FROM USER_IND_EXPRESSIONS
WHERE TABLE_NAME = 'EMP';
[실행결과]
| INDEX_NAME | COLUMN_EXPRESSION | COLUMN_POSITION |
1 | IDX_EMP_JOB_SAL | "SAL" | 2 |
2 | IDX_SUBSTR_ENAME | SUBSTR("ENAME",0,1) | 1 |
IDX_EMP_JOB_SAL 인덱스는 job 오름차순, sal 내림차순으로 생성된 복합 인덱스이며 내림차순 인덱스인 경우 함수기반 인덱스로 생성 됩니다. IDX_SUBSTR_ENAME 인덱스의 생성 형태는 column_expression를 확인하면 확인하면 됩니다. column_position은 0부터 시작되며 EMP 테이블은 empno, ename, sal 컬럼 순 입니다.
#함수기반인덱스, #인덱스, #오라클인덱스, #functionbasedindex, #ORACLE, #ORACLE교육, #오라클강의, #오라클강좌



