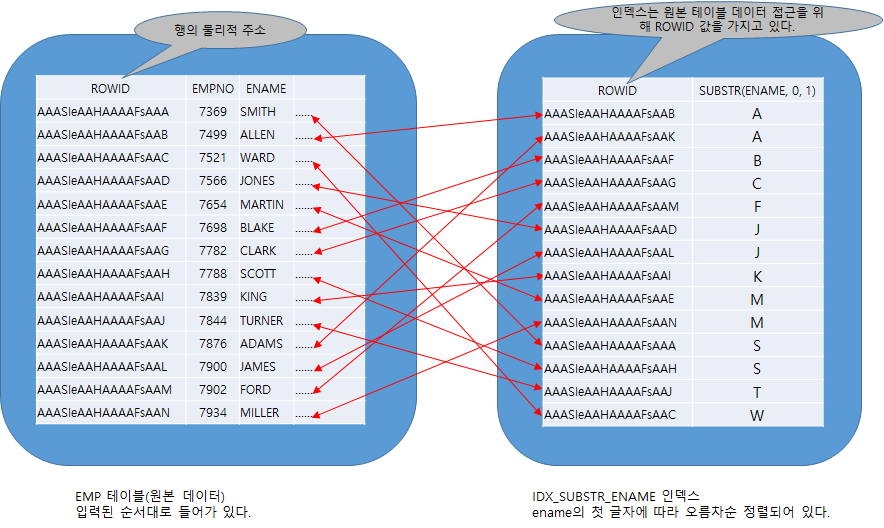
동의어synonym는 테이블, 뷰, 시퀀스, 프로그램 유닛(함수, 프로시저, 패키지)에 대한 별명이며 공용(public), 전용(private) 두가지 형태로 작성 가능 합니다. 공용 동의어public synonym는 DBA 권한을 가진 사용자만이 생성 가능하고 모든 계정에서 접근 가능 하며, 전용 동의어private synonym는 동의어로 작성 될 객체에 대한 접근 권한을 얻은 사용자가 작성하는 동의어로 해당 USER에서만 사용 가능 합니다.
동의어는 단순한 별칭 이므로 데이터 딕셔너리data dictionary의 정의 외 다른 저장 공간이 필요하지는 않습니다.
동의어는 보안과 편의성 때문에 사용되는데 객체의 이름 및 소유자를 가릴 수 있습니다. 또 분산 환경에서 원격 객체에 대한 위치 투명성 제공합니다. 동의어로 만들어진 테이블의 이름을 바꾸거나 이동해야하는 경우 동의어 만 다시 정의하면되기 때문에 이 방법이 유용하며 동의어를 기반으로하는 응용 프로그램은 수정없이 계속 사용 가능 합니다.
동의어는 스키마 오브젝트를 직접 참조 합니다. 예를 들어 SCOTT 계정에서 EDU라는 계정의 STUDENT 테이블을 참조할 때 EDU.STUDENT 라고 써주어야 하는데 여러 번 사용되는 경우에는 이름이 길어서 불편 합니다. 이러한 경우 EDU.STUDENT 에 대한 동의어를 만들어서 사용하면 편리 합니다.
[기본형식]
CREATE [PUBLIC] SYNONYM [schema.] synonym_name FOR [schema.]object; PUBLIC : 공용 동의어를 정의하며 생략하면 전용 동의어를 정의합니다. |
실제 RABBIT 사용자를 생성하고 테이블을 만들어서 SCOTT 계정에서 동의어를 만들고 이를 딕셔너리 뷰에서 확인 후 삭제해 보겠습니다.
실습
실습을 위한 RABBIT 사용자 계정을 생성합니다. 오라클12C 이후 사용자 생성시 앞에 C##을 붙여야만 하는데 이전 방식과 동일한 방식으로 사용자를 생성하기 위해 세션 레벨에서 “_ORACLE_SCRIPT”=TRUE라고 설정합니다.
현재 세션에서 오라클 12C 이전 스크립트방식을 지원하면서 사용자를 생성하기 위해 _ORACLE_SCRIPT를 TRUE로 설정하세요. |
ALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;
<실행결과>
Session이(가) 변경되었습니다.
새로운 사용자 계정을 생성 합니다.
ID : RABBIT, PASSWORD : RABBIT으로 사용자 계정을 생성하세요. |
CREATE USER RABBIT IDENTIFIED BY RABBIT;
<실행결과>
User RABBIT이(가) 생성되었습니다.
오라클에 접속을 하기위한 롤role과 테이블 등을 생성할 수 있는 롤을 부여합니다. 롤은 권한privilege을 여러개 합쳐놓은 것 입니다.
생성한 사용자 계정에 CONNECT, RESOURCE 롤을 부여하세요. |
GRANT CONNECT, RESOURCE TO RABBIT;
<실행결과>
Grant을(를) 성공했습니다.
CONNECT 롤에는 ALTER SESSION, CREATE SESSION, CREATE CLUSTER, CREATE SYNONYM, CREATE DATABASE LINK, CREATE TABLE, CREATE SEQUENCE, CREATE VIEW 권한이 포함되어 있고, RESOURCE 롤에는 CREATE CLUSTER, CREATE INDEXTYPE, CREATE OPERATOR, CREATE PROCEDURE, CREATE SEQUENCE
CREATE TABLE, CREATE TRIGGER, CREATE TYPE 권한이 포함되어 있습니다.
오라클에 접속을 하기위한 롤role과 테이블 등을 생성할 수 있는 롤을 부여합니다. 롤은 권한privilege을 여러개 합쳐놓은 것 입니다.
생성한 사용자 계정에 CONNECT, RESOURCE 롤을 부여하세요. |
GRANT CONNECT, RESOURCE TO RABBIT;
<실행결과>
Grant을(를) 성공했습니다.
오라클11g 까지는 RESOURCE 롤에 UNLIMITED TABLESPACE 권한이 있어 RESOURCE 롤을 부여후 CREATE TABLE이 가능했지만 12C 이후에는 별도로 부여해야 합니다.
생성한 사용자 계정에 UNLIMITED TABLESPACE 권한을 부여하세요. |
GRANT UNLIMITED TABLESPACE TO RABBIT;
<실행결과>
Grant을(를) 성공했습니다.
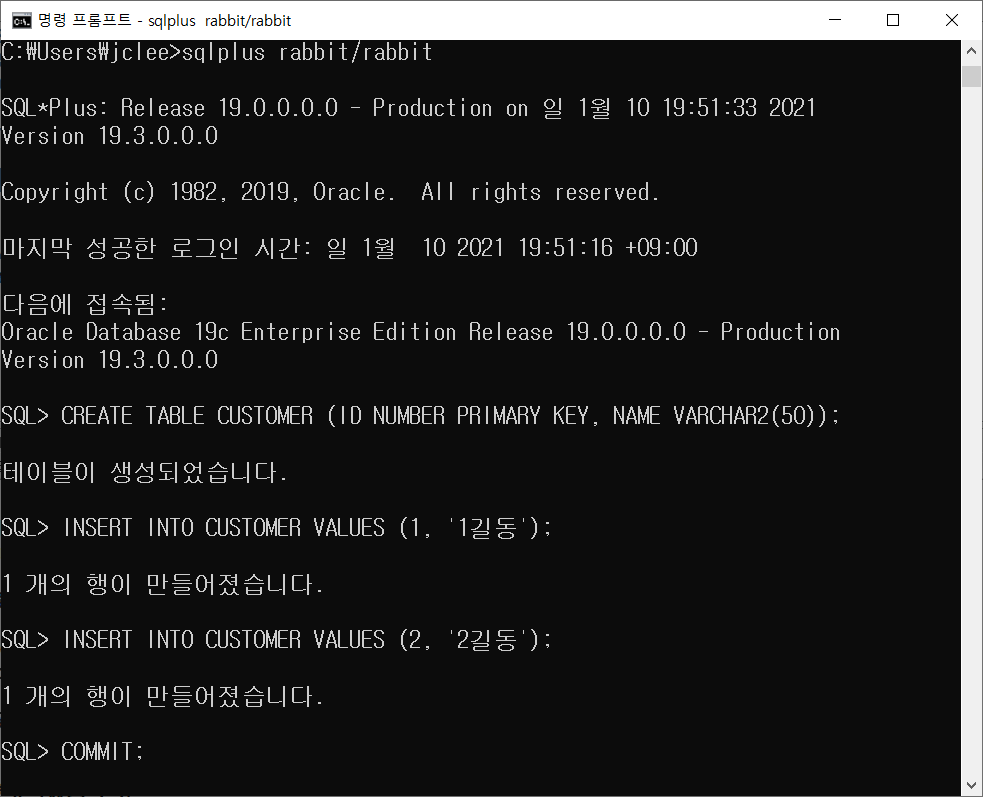
RABBIT 계정으로 명령프롬프트를 이용하여 접속 후 테이블을 생성하고 데이터 2건을 입력 합니다.
생성한 사용자 계정에서 테이블 및 데이터를 생성 하세요. |
SQL Developer의 SCOTT 계정에서 RABBIT 계정의 CUSTOMER 테이블을 SELECT 합니다. SCOTT 계정은 DBA 롤을 부여받은 계정이므로 SELECT 되지만 일반 다른 사용자에서는 CUSTOMER 테이블에 대한 SELECT 권한을 부여 받아야 합니다.
RABBIT 계정의 CUSTOMER 테이블을 SELECT 하세요. |
SELECT * FROM RABBIT.CUSTOMER;
<실행결과>
ID | NAME | |
1 | 1 | 1길동 |
2 | 2 | 2길동 |
RABBIT.CUSTOMER에 대한 공용 동의어를 생성합니다. 공용 동의어는 모든 사용자 계정에서 접근 가능 합니다.
RABBIT.CUSTOMER에 대한 동의어 RC를 생성 합니다. |
CREATE PUBLIC SYNONYM RC FOR RABBIT.CUSTOMER;
<실행결과>
SYNONYM RC이(가) 생성되었습니다.
동의어를 통해 데이터를 조회 합니다.
동의어 RC를 SELECT 합니다. |
SELECT * FROM RC;
<실행결과>
ID | NAME | |
1 | 1 | 1길동 |
2 | 2 | 2길동 |
생성한 동의어를 딕셔너리 뷰에서 조회 합니다.
동의어 RC를 SELECT 합니다. |
SELECT OWNER, SYNONYM_NAME, TABLE_OWNER
FROM DBA_SYNONYMS
WHERE SYNONYM_NAME = 'RC' ;
#오라클교육, #ORACLE교육, #오라클동의어, #동의어, #ORACLE, #synonym, #OracleSynonym
<실행결과>
OWNER | SYNONYM_NAME | TABLE_OWNER | |
1 | PUBLIC | RC | RABBIT |