오라클 옵티마이저 통계정보, DBMS_STATS, 테이틀/컬럼/인덱스 통계정보, 오라클교육, ORACLE동영상교육, 자바학원, 오라클학원,JAVA학원
https://www.youtube.com/watch?v=eQmUdTkIDm8&list=PLxU-iZCqT52DFRbLFQIgGUFp-5En2DYRG&index=34

https://www.youtube.com/watch?v=SYUxsqhzNRQ&list=PLxU-iZCqT52DFRbLFQIgGUFp-5En2DYRG&index=33

https://www.youtube.com/watch?v=CK4UzRwkDVs&list=PLxU-iZCqT52DFRbLFQIgGUFp-5En2DYRG&index=32

https://www.youtube.com/watch?v=9rvdwAcz4D0&list=PLxU-iZCqT52DFRbLFQIgGUFp-5En2DYRG&index=31

https://www.youtube.com/watch?v=2DjEl1PYzWo&list=PLxU-iZCqT52DFRbLFQIgGUFp-5En2DYRG&index=30
옵티마이저 통계정보
DBMS_STATS
테이블, 컬럼 통계정보
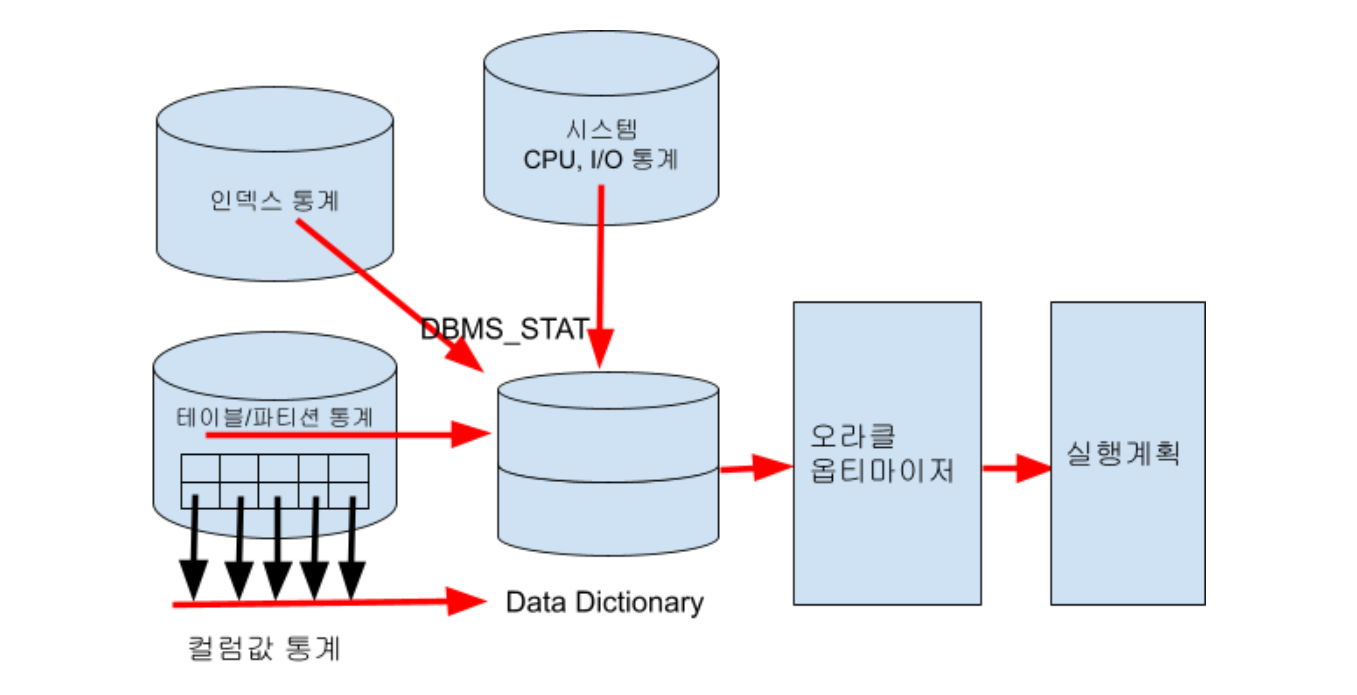
DBMS-STATS를 알아보기 전에 테이블 및 컬럼의 통계정보가 무엇인지 알아보도록 하겠습니다.
[실습]
| 사원(EMP) 테이블은 14개의 행이 있고 테이블 통계정보와 컬럼 통계정보가 생성되어 있습니다. USER_TAB_COL_STATISTICS에는 컬럼의 통계정보(유일한 값의수, LOW/HIGH VALUE, DENSITY, 버켓의 수, 널 값의 수, 컬럼값의 평균길이, 히스토그램생성여부)가, USER_TAB_STATISTICS에는 테이블에 대한 통계정보(행의수, 블록수, 평균레코드길이)가 생성되어 있는데요 확인해 보겠습니다. EMP 테이블은 14건 이고 컬럼의 통계정보를 조회하면 다음과 같습니다. NUM_DISTINCT 값은 유일한 값의 수 입니다. density(밀도)는 컬럼값을 하나의 조건으로 등호(=)로 검색시 선택도를 나타내는데, histogram을 사용할 수 없는 경우(값의 출현빈도를 고려하지않은 경우) 컬럼에 존재하는 값이 한가지라면 1 이고 5가지이면 0.2가 되는데, 이값은 1/NUM_DISTINCT 입니다. 물론 출현빈도를 고려한 histogram이 있는 경우 density는 오라클에서 알아서 생성을 합니다. histogram이란 컬럼값의 출현빈도, 분포/분산정도를 그래피컬하게 나타낸 것이며 값의 분포가 특정값에 치우치는 경우 히스토그램을 이용해서 정확한 예상 레코드 건수(Cardinality)를 측정 가능 합니다. histogram은 컬럼의 값이 Skew 되어 있을때 특히 장점이 있는데, 컬럼값이 Skew 되었다는 것은 값의 출현빈도가 특정 값에 몰려있다는 이야기 입니다. histogram이 없다면 Cardinality 계산이 맞지 않을 것 입니다. histogram값이 frequence인 경우는 값별로 빈도수를 저장하는 도수분포 히스토그램을 뜻하며 값의수 = 버킷수 입니다. histogram을 이용하여 옵티마이저는 더 정확한 카디널리티를 추정하고 정확한 실행을 생성할 수 있습니다 NUM_BUCKETS 값은 열에 대한 히스토그램 버켓수(값을 담는 바구니)로 histogram이 있는 경우 NUM_DISTINCT 값이며 없는 경우 1 입니다. deptno 컬럼의 경우 buckets 값은 3 입니다. EMP 테이블은 14건이 있고 직무(JOB) 컬럼은 CLERK, SALESMAN, MANAGER, PRESIDENT, ANALYST 5종류의 값을 가지고 있습니다. job컬럼은 유일한 값의 종류가 5이고, 그러므로 density가 0.2이고 histogram 이 없습니다. 모든 컬럼값들의 출현빈도가 동일하다고 가정을 하는데요, 그래서 아래처럼 예측건수와 실제건수가 차이가 날수 있다는것 입니다. Cardinality는 WHERE절의 조건( predicate)에 의해서 추출되는 행의 수를 의미합니다. job 컬럼의 Cardinality는 predicate가 하나(where절의 조건이 하나면)면 선택도(Selectivity)가 density와 같은 의미로 생각되어 NUM_ROWS * DENSITY = 14 * 0.2 = 2.8 정도 되는데, 사실 Cardinality는 NUM_ROWS * 선택도(Selectivity) 입니다. 컬럼의 값들이 WHERE절에서 AND, OR 로 엮이면 선택도가 변하게 됩니다. 정확한 Cardinality 예상은 최적의 실행계획을 만드는데 중요한 요인입니다. 다음은 EMP 테이블의 테이블통계정보를 조회한 내용입니다. SELECT OBJECT_TYPE, NUM_ROWS, BLOCKS, AVG_ROW_LEN FROM USER_TAB_STATISTICS WHERE TABLE_NAME = 'EMP'; OBJECT_TYPE NUM_ROWS BLOCKS AVG_ROW_LEN —-------------------------------------------------------------------------------------------- TABLE 14 5 42 |
- 오라클의 Analyze 명령, DBMS_UTILITY, DBMS-STATS 등을 이용하여 옵티마이저 통계정보를 생성할 수 있는데 DBMS-STATS 사용을 권장하고 있습니다.
- 옵티마이저 통계정보는 데이터베이스 모든 오브젝트에 대한 자료를 모아 기술한 통계인데 데이터 딕셔너리(Data Dictionary)에 저장되며 오라클 옵티마이저는 이 통계정보를 바탕으로 효율적인 SQL 실행계획을 만들어 냅니다. 물론 생성한 통계정보를 지정한 별도의 테이블에 저장 할 수도 있습니다.
- DBMS_STATS 패키지는 SQL 성능을 향상 시키기 위해 Optimizer Statistics(옵티마이저 통계정보)를 수집합니다.
- 오라클은 테이블이나 인덱스와 같은 데이터베이스 오브젝트에 대한 통계 정보 생성, 삭제, 익스포트, 임포트를 용이하게 하기 위해 DBMS_STATS 패키지를 제공하는데 이 패키지를 이용하면 테이블이나 인덱스의 모든 데이터를 근간으로 통계 정보를 생성할 수 있습니다.
- 대용량의 테이블이라면 모든 데이터를 가지고 액세스 경로를 추측하는 것보다 샘플링 데이터를 가지고 추측하는 것이 훨씬 용이하다. 대체로 샘플링 데이터는 5% 이하로 ROW나 BLOCK에 만들며 DBMS_STATS 패키지의 automatic sampling 프로시저를 이용하면 됩니다.
- 통계정보 수집용 별도의 테이블 생성은 DBMS_STATS 패키지의 create_stat_table 프로시저를 이용하여 만들면 됩니다.
- DBMS_STATS 패키지에는 몇 개의 유용한 프로시저가 있는데 아래와 같습니다.
gather_database_ stats: 데이터베이스의 모든 Object에 대한 통계 정보 생성.
gather_system_stats : CPU, I/O등 시스템 Performance 통계정보 생성
gather_dictionary_ stats: SYS, SYSTEM 스키마의 Object에 대한 통계 정보 생성.
gather_schema_ stats: 해당 스키마의 모든 Object에 대한 통계 정보 생성.
gather_table_stats : 테이블과 그 테이블과 연관된 인덱스에 대한 통계 정보 생성.
gather_index_stats : 인덱스에 대해 통계 정보를 생성.
-- 여기에서 사용된 인자는 접속한 계정, 통계정보 수집용 테이블 이름, 테이블스페이스 이름이다.
-- 사용자 스키마에 통계정보를 보유할 stat_tab 이라는 이름의 테이블을 생성하며
-- 이 테이블의 컬럼과 타입은 DBMS_STAT 패키지를 통해서만 접근되어야 합니다.
SQL> execute dbms_stats.create_stat_table(USER, 'stat_tab');
PL/SQL 처리가 정상적으로 완료되었습니다.
-- 현재 로그온한 스키마 계정의 OBJECT 대해 통계 정보를 생성합니다.
SQL> execute dbms_stats.gather_schema_stats(ownname => USER);
PL/SQL 처리가 정상적으로 완료되었습니다.
-- 현재 로그온한 스키마 계정의 EMP 테이블에 대해 통계 정보를 생성합니다.
SQL> execute dbms_stats.gather_table_stats(USER, 'emp');
PL/SQL 처리가 정상적으로 완료되었습니다.
-- 데이터 딕셔너리에서 생성된 통계정보 확인, LAST_ANALYZED 칼럼을 확인하세요.
SQL>SELECT * FROM USER_TABLES WHERE TABLE_NAME = ‘EMP’;
--EMP 테이블의 통계정보를 생성하면서 연관된 인덱스의 통계정보도 생성
SQL>exec dbms_stats.gather_table_stats(← 테이블 통계정보 생성.
USER, ‘emp’',
cascade => true); ← 테이블의 각 인덱스에서 GATHER_INDEX_STATS 프로시저를 실행하는 것과 같습니다.
--EMP 테이블 및 컬럼 및 연관 인덱스의 통계정보를 생성
--for all columns size 1 : 모든 컬럼의 통계정보를 생성하는데 컬럼 내에 존재하는 여러 가지 값들의 출현빈도, 값의 분포를 모두 동일한 값 1로 간주, 즉 histogram 을 사용하지 않는 것이며, where 조건에 들어오는 특정 컬럼에 대한 값의 변화에 따라서 실행계획이 변경될 가능성을 없다는 뜻입니다.
-- method_opt의 기본값은 for all columns size auto로 컬럼값의 출현빈도인 histogram 생성을 오라클이 알아서 합니다.
SQL>exec dbms_stats.gather_table_stats(
USER, 'emp',
cascade => true,
method_opt => ‘for all column size 1’);
--EMP 테이블과 인덱스 컬럼의 통계정보를 생성(모든 컬럼의 통계정보가 생성되는 것은아님)
SQL>exec dbms_stats.gather_table_stats(
USER, 'emp',
method_opt => ‘for all indexed columns’’);
--EMP테이블의 15%의 행을 가지고 테이블, 컬럼, 연관된 인덱스의 통계정보를 생성
--method_opt의 기본값은 “FOR ALL COLUMNS SIZE AUTO”으로 테이블 통계정보 생성할 때 컬럼의 통계정보도 생성을 하는데 Histogram 의 생성여부를 오라클이 알아서 합니다.
SQL>exec dbms_stats.gather_table_stats(
USER, 'emp',
cascade => true,
estimate_percent=>15);
--EMP 테이블의 테이블, 컬럼의 통계정보를 생성(연관된 인덱스의 통계정보, histogram 생성안함)
SQL>exec dbms_stats.gather_table_stats(
USER, 'myemp1',
method_opt => ‘for all columns size 1’);
-- 현재 EMP 테이블의 통계정보를 STAT_TAB으로 EXPORT
SQL> execute dbms_stats.export_table_stats (USER, 'emp',null,'stat_tab');
PL/SQL 처리가 정상적으로 완료되었습니다.
-- 딕셔너리와 STAT_TAB의 통계정보의 차이를 비교, 현재는 차이가 없다.
SQL> select * from table(dbms_stats.diff_table_stats_in_stattab(USER,'emp','stat_tab'));
REPORT MAXDIFFPCT
-------------------------------------------------------------------------------- ----------
################################################### 0
-- 통계정보 수집용 테이블 삭제
SQL> execute dbms_stats.drop_stat_table(USER,'stat_tab');
PL/SQL 처리가 정상적으로 완료되었습니다.
이번에는 시스템과 관련된 통계 정보를 생성해 보겠습니다.
DBMS_STATS를 이용하여 CBO(cost based optimizer)에게 system performance 통계정보를 제공 할 수 있는데 이 패키지는 CPU 사용과 I/O 퍼센트 등의 정보를 통계정보 생성시 추가한다. dbms_stats.gather_system_stats 프로시저를 이용하고 파라미터는 다음과 같다.
Gathering_mode : 통계 정보에 대한 수집을 특정한 시기 또는 기간에 하는 경우에는 interval 이나 start/stop 값을 주면 되고 noworkload라고 하면 시스템은 통계 정보를 general하게 수집한다.
Interval : Gathering_mode에서 interval이라고 한 경우에만 사용한다.
Stattab : 시스템의 통계 정보가 모아질 테이블을 기술한다.
Statown : 시스템의 통계 정보가 모아질 테이블의 Owner를 기술한다. (현재 패키지를 실행 할 Schema와 다를 경우에 기술)
SQL> begin
dbms_stats.gather_system_stats (
gathering_mode => 'interval',
interval => 60, //분단위
stattab => 'stat_tab',
statown => USER);
end;
/
PL/SQL 처리가 정상적으로 완료되었습니다.
DBMS_STATS.gather_system_stats를 사용하기 전에 job_queue_processes 매개변수를 SET 시켜야 하는데 기본값은 0, 양수값으로 세팅해야 한다. 그렇지 않으면 gather_system_stats 프로시저가 동작하지 않을 수 있다. 현재 세션에서 이 값을 다이나믹하게 설정하려면 alter system set job_queue_processes = 20 이라고 하면 된다.
이상에서 설명드린 부분외에 일한 통계정보를 DBMS_STATS 패키지에서 자동으로 생성하는 방법도 있지만 본 강좌에서는 설명드리지는 않겠습니다.
#오라클, #옵티마이저, #통계정보, #DBMS_STATS, #테이틀통계정보, #컬럼통계정보, #옵티마이저통계정보, #오라클교육, #ORACLE동영상, #ORACLE교육, #오라클학원, #ORACLE학원, 오라클, 옵티마이저, 통계정보, DBMS_STATS, 테이틀통계정보, 컬럼통계정보, 옵티마이저통계정보, 오라클교육, ORACLE동영상, ORACLE교육, 오라클학원, ORACLE학원,



