JPA로깅, Spring JPA 엔티티매니저(EntitiyManager), JPA쿼리 종류, Querydsl, NativeSQL, Criteria, JPA학원, Spring학원, 자바학원교육
http://ojc.asia/bbs/board.php?bo_table=LecJpa&wr_id=362
ojc.asia
http://ojc.asia/bbs/board.php?bo_table=LecJpa&wr_id=363
ojc.asia
https://www.youtube.com/watch?v=RdIPh1iGm5A&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=7

https://www.youtube.com/watch?v=2zovSWrKhmo&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=8

https://www.youtube.com/watch?v=rwDOqrM2B9Q&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=2

https://www.youtube.com/watch?v=jrKfAdJXq7Q&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=9

스프링 JPA로깅, Log4J, Logback-spring
Logging
SQL을 대신 작성해 주는 JPA 기술을 사용하다 보면 과연 적합한 SQL을 사용하는지 궁금해지기 마련입니다. 특히나 테이블 크기가 크고 복잡한 조인 쿼리를 사용해서 여러 테이블의 데이터를 구해야 하는 경우 JPA가 최적의 SQL을 작성해서 사용하는지 검토해 볼 필요가 있습니다.
오랜 역사의 오라클데이터베이스도 때때로 최적의 쿼리를 사용하지 않고 있는 모습을 볼 수 있습니다. 그럴 때 힌트를 사용해서 개발자가 직접 쿼리의 실행계획을 조정할 필요가 있습니다. 이와 마찬가지로 JPA가 작성해서 사용하는 쿼리도 최적의 쿼리가 아닐 수 있습니다. 어떤 SQL 쿼리를 사용하느냐에 따라 성능의 차이가 날 수 있기 때문에 개발자가 직접 확인 해야 합니다. 이를 위해 프로젝트에 로깅기술을 적용해서 사용된 쿼리를 살펴보기 쉽도록 만들 필요가 있습니다.
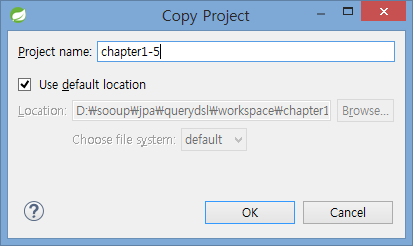
프로젝트 생성
앞서 작업한 프로젝트 chapter1-4를 선택한 상태에서 ctrl+c, ctrl+v 키를 연속으로 눌러서 소스 전체를 복사해 chapter1-5라고 명명하면서 프로젝트를 추가합니다.
디펜던시 설정
pom.xml 파일에 다음 설정을 추가합니다.
<dependency>
<groupId>org.bgee.log4jdbc-log4j2</groupId>
<artifactId>log4jdbc-log4j2-jdbc4.1</artifactId>
<version>1.16</version>
</dependency>
로깅 환경설정
환경설정파일에 로깅을 위한 설정을 추가합니다.
application.properties
# DATASOURCE
#spring.datasource.url=jdbc:mysql://localhost:3306/testdb?createDatabaseIfNotExist=true
spring.datasource.url=jdbc:log4jdbc:mysql://localhost:3306/testdb?createDatabaseIfNotExist=true
#spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.driver-class-name=net.sf.log4jdbc.sql.jdbcapi.DriverSpy
# Logging
logging.config=classpath:logback-spring.xml
기존 드라이버 설정은 # 주석으로 막고 드라이버 스파이를 사용하도록 변경합니다. 로깅설정의 상세한 내용은 logback-spring.xml에 작성합니다. logback은 log4j를 업그레이드 한 기술입니다.
logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
jdbc.sqlonly : Logs only SQL
jdbc.sqltiming : Logs the SQL, post-execution, including timing execution statistics
jdbc.audit : Logs ALL JDBC calls except for ResultSets
jdbc.resultset : all calls to ResultSet objects are logged
jdbc.connection : Logs connection open and close events
-->
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- By default, encoders are assigned
the type ch.qos.logback.classic.encoder.PatternLayoutEncoder -->
<encoder>
<pattern>
%d{yyyyMMdd HH:mm:ss.SSS} [%thread] %-3level %logger{5} -%msg %n
</pattern>
</encoder>
</appender>
<logger name="jdbc" level="OFF" />
<logger name="jdbc.sqlonly" level="DEBUG" additivity="false">
<appender-ref ref="STDOUT" />
</logger>
<logger name="jdbc.resultsettable" level="DEBUG" additivity="false">
<appender-ref ref="STDOUT" />
</logger>
<include resource="org/springframework/boot/logging/logback/base.xml"/>
<appender name="dailyRollingFileAppender"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<prudent>true</prudent>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>applicatoin.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<pattern>
%d{yyyy:MM:dd HH:mm:ss.SSS} %-5level --- [%thread] %logger{35} : %msg %n
</pattern>
</encoder>
</appender>
<logger name="org.springframework.web" level="INFO"/>
<logger name="org.thymeleaf" level="INFO"/>
<logger name="org.hibernate.SQL" level="INFO"/>
<logger name="org.quartz.core" level="INFO"/>
<logger name="org.h2.server.web" level="INFO"/>
<root level="INFO">
<appender-ref ref="STDOUT" />
<!-- 프로젝트 루트 폴더에서 파일생성을 확인 (applicatoin.20YY-MM-DD.log) -->
<appender-ref ref="dailyRollingFileAppender" />
</root>
</configuration>
■ "STDOUT" 설정으로 로깅정보가 콘솔에 출력됩니다.
■ "dailyRollingFileAppender" 설정으로 로깅 정보가 프로젝트 루트에 파일로 기록됩니다.
log4jdbc.log4j2.properties
로깅을 처리할 때 로거가 참조하는 설정정보를 알려줍니다.
log4jdbc.spylogdelegator.name=net.sf.log4jdbc.log.slf4j.Slf4jSpyLogDelegator
# multi-line query display
log4jdbc.dump.sql.maxlinelength=0
테스트
스프링 기동 로그 살펴보기
application.properties 파일에 spring.jpa.hibernate.ddl-auto=create 설정으로 프로젝트가 기동 시 기존 테이블을 삭제하고 다시 생성할 것입니다. 로그 정보에서 관련 로그내역을 찾아보세요.
drop table if exists employee
create table employee (empno bigint not null, ename varchar(255), job varchar(255), primary key (empno)) ENGINE=InnoDB
data.sql에 작성된 쿼리를 처리하는지 확인합니다.
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7839,'KING','PRESIDENT');
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7566,'JONES','MANAGER');
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7698,'BLAKE','MANAGER');
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7782,'CLARK','MANAGER');
브라우저로 접근해서 데이터를 요청하여 테스트 합니다.
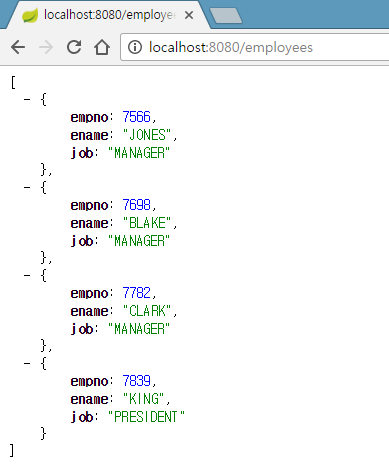
질의 관련 로그 살펴보기
드라이버스파이는 조회쿼리인 경우 결과를 보기 좋게 테이블로 표시해 줍니다.
select employee0_.empno as empno1_0_, employee0_.ename as ename2_0_, employee0_.job as job3_0_ from employee employee0_
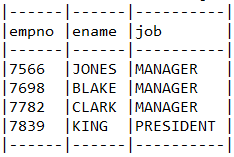
쿼리의 퍼포먼스를 판단할 수 있는 실행계획까지는 보여주지 않으므로 로그에 표시된 쿼리를 데이터베이스 전용 프로그램에서 실행하여 실행계획을 살펴 보시기 바랍니다.
#JPA, #로깅, #스프링로깅, #Log4J, #스프링교육, #자바교육, #오라클교육,#스프링학원, #자바학원, #SQL학원, #오라클학원, JPA, 로깅, 스프링로깅, Log4J, 스프링교육, 자바교육, 오라클교육,스프링학원, 자바학원, SQL학원, 오라클학원
2.JPA
JPA의 구현체인 Hibernate의 엔티티매니저는 자체적으로 CRUD 메소드를 제공합니다. EntityManager의 find 메소드를 이용하면 키 값으로 하나의 로우를 조회할 수 있는데 이 메소드는 데이터를 모델객체에 담아서 돌려줍니다.
모델객체와 관계를 맺고 있는 다른 모델객체들의 데이터는 모델객체들의 연관관계에 따라 EAGER 또는 LAZY 로딩 정책이 적용됩니다.
Dept : Emp = 1 : N
예를 들어 부서(Dept)는 많은 직원(Emp)을 갖고 있고 직원은 한 부서에 속한다고 하면 두 개의 객체의 연관관계는 1:N이 됩니다. 부서 객체를 대상으로 질의하면서 부서 객체와 연관관계에 있는 직원객체도 같이 데이터를 구할 것인지 판단해야 하는데 N의 연관관계에 해당하는 경우 기본적으로 LAZY 로딩정책을 적용합니다. 그 반대로 직원 객체를 대상으로 질의하는 경우 직원 객체와 연관관계에 있는 부서객체도 같이 데이터를 구할 것인지 결정해야 하는데 1의 연관관계에 해당하는 경우 기본적으로 EAGER 로딩적책을 적용합니다.
EAGER 로딩정책인 경우 대상 모델객체의 데이터를 구할 때 연관된 모델객체들의 데이터도 같이 구해 옵니다. LAZY 로딩인 경우에는 대상 모델객체의 데이터만 구합니다. 추후에 대상 객체의 객체 그래프 탐색을 사용하는 시점에서 실제 데이터 대신 갖고 있는 프록시객체를 호출하여 그 시점에서 연관된 모델 개체의 데이터를 구해 옵니다. EAGER 로딩은 개발자 입장에서는 편리한 기능이지만 사용하지 않는 데이터를 구하기 위한 질의를 매번 수행하는 것은 낭비가 되므로 삼가야 합니다.
질의의 과도한 사용을 줄이기 위해서 JPA 기술을 사용할 때 엔티티매니저가 쿼리를 어느 시점에 얼마나 사용하는지, 사용하지도 않는 데이터를 구하기 위해 여러 쿼리가 사용되고 있지는 않는지 살펴 볼 필요가 있습니다. 바로 이 부분이 JPA를 사용하는 개발자가 갖춰야 할 핵심역량이라고 할 수 있습니다.
기본 로딩정책은 LAZY로 설정하고 필요할 때 점진적으로 EAGER 로딩정책을 적용해 가는 방식으로 관리하는 것이 좋습니다.
2.1. EntityManager
엔티티매니저가 제공하는 메소드를 이용하여 데이터를 구하는 코드를 살펴 보겠습니다.
Dept dept = em.find(Dept.class, 1L); // #1
Set<Emp> emps = dept.getEmps() ; // #2
#1 설명
첫 번째 파라미터 자리에는 엔티티 클래스를 지정합니다. 두 번째 파라미터 자리에는 고유한 키 값을 지정합니다. 1L "Long" 자료형을 사용한 이유는 엔티티 클래스 내에 존재하는 키의 역할을 수행하는 필드변수의 자료형을 따른 것입니다.
엔티티매니저는 @Entity 어노테이션이 붙어 있는 모델 클래스를 애플리케이션이 기동할 때 파악합니다. 따라서 파라미터로 엔티티 클래스를 주면 엔티티매니저는 어느 테이블을 사용해야 하는지 알고 있습니다.
만약 앞에서 같은 요청을 한 번이라도 이미 했다면 엔티티매니저는 Persistence Context를 통해 해당 모델객체를 이미 갖고 있는 상태이므로 갖고 있는 객체를 바로 돌려 줄 것입니다. Persistence Context는 데이터베이스에 질의하여 얻어 온 데이터를 보관하는 모델 객체를 원본과 복사본으로 관리하며 개발자에게 돌려 주는 객체는 복사본 객체입니다. 원본을 따로 보관하는 것은 트랜잭션이 끝날 때 데이터의 변화를 체크하여 이를 반영하기 위한 행동입니다. 원본 객체를 보관했다가 같은 데이터를 요청 받으면 갖고 있는 객체를 바로 주는 기능을 1차 캐시 기능이라고 부릅니다.
#2 설명
직원이 여러 부서에 배치되는 것이 아니라 부서가 여러 직원을 갖고 있는 것이 일반적인 모습이므로 Dept와 Emp의 관계는 1:N이 됩니다. 위 코드 중 #1에 해당하는 코드는 키에 맞는 부서 데이터를 요청하고 있습니다. 이 경우 N에 해당하는 디폴트 로딩정책은 LAZY 이므로 dept 변수가 가리키는 객체는 dept 테이블 데이터만 있고 직원객체와 연관된 데이터는 없는 상태입니다. 이러한 로딩정책을 기본적으로 사용하는 이유는 N에 해당하는 테이블의 로우의 개수가 수백만 건이 넘을 정도로 매우 클 수도 있기 때문에 요청할 때 마다 연관 테이블의 데이터를 가져오는 행동방식은 불합리하기 때문입니다.
dept 변수가 가리키는 객체 내에 emps 필드변수는 값을 갖고 있는 상태가 아니라 값을 구할 수 있는 프록시 객체를 대신 가리키고 있습니다. 개발자가 데이터를 사용하기 위해서 요청하는 시점에 프록시 객체를 기동하여 데이터를 구해 옵니다. dept.getEmps 메소드를 호출하는 시점에 이렇게 처리됩니다.
일부 데이터만 사용하면 되는데 전체 데이터를 메모리에 올려두고 사용하는 것은 메모리관리 측면에서 보면 매우 비효율적입니다. 그러므로 개발자는 쿼리를 적절히 조절해서 필요한 시점에 필요한 만큼의 데이터를 구해서 사용해야 할 것입니다.
JPA를 사용하면 개발자는 엔티티매니저가 관리하는 객체를 대상으로 데이터를 요구하게 됩니다. 데이터를 엔티티매니저에게 요구하기 위해서 SQL과 거의 비슷한 JPQL을 사용합니다. 개발자가 데이터베이스에 직접 질의하는 것이 아니라 엔티티매니저의 엔티티 객체를 대상으로 질의하기 때문에 SQL 대신 JPQL을 사용하는 것이며 이를 객체지향 쿼리라고 부릅니다.
2.2. JPA에서 사용 가능한 쿼리의 종류
2.2.1. JPQL
JPQL은 Java Persistence Query Language의 약자입니다. 객체지향 쿼리이므로 특정 DB SQL에 의존적이지 않습니다. JPQL은 엔티티매니저에 의해 SQL로 변경되어 사용됩니다. 엔티티매니저는 프로젝트 기동 시 설정을 참고하여 어느 데이터베이스를 위한 Dialect를 사용해야 하는지 파악합니다.
JPQL은 문자열 형태의 SQL과 비슷한 구문형태로 작성하므로 익히는데 많은 시간이 소요되지 않습니다. JPQL 작성 시 주의할 점은 테이블에 질의하는 것이 아니라 엔티티 객체를 대상으로 질의하는 것이므로 사용해야 할 대상 키워드는 테이블명이 아니라 엔티티 클래스명이라는 점 입니다.
SQL이든 JPQL이든 쿼리를 문자열로 작성하면 그 자체로는 단순한 문자열이므로 컴파일 타임에서 구문 오류를 잡는 것은 불가능합니다. 쿼리를 데이터베이스에 질의해 보아야 정상적인 쿼리인지 확인할 수 있습니다. 오랫동안 이 문제는 개발자들의 골칫거리였습니다. 쿼리가 정상적으로 수행될 수 있는지 테스트하기 위해서는 DB가 존재해야 하고 그런 환경을 구성하는 것은 시간적으로나 비용적으로 테스트를 수월하게 수행하지 못하게 하는 요소입니다.
이에 따라 컴파일 타임에서 SQL 구문 오류를 잡아내기 위해서 Criteria, Querydsl 같은 기술이 등장했습니다. 이러한 기술은 메소드 기반 형태로 쿼리구문을 작성합니다. 쿼리를 메소드로 작성하면 컴파일 타임에서 타입 세이프 오류를 발견하는 것이 가능하게 됩니다. 이는 닷넷의 링크와 비슷한 개념입니다.
대표적인 JPA 구현체인 Hibernate는 자바표준인 JPA기술을 지원하고 부가적으로 Hibernate에서만 사용할 수 있는 추가적인 기능이 존재합니다. 이는 자바 표준 @Inject 어노테이션이 있는데 스프링이 @Autowired 어노테이션을 추가적으로 사용하는 모습과 비슷합니다. Hibernate를 직접 이용해서 개발한다고 말하는 경우 JPQL이라는 용어 대신 Hibernate Query Language라는 용어를 사용하여 구분 합니다.
String jpql = "select e from Emp e where e.ename = :ename";
List<Emp> result = em.createQuery(jpql, Emp.class)
.setParameter("ename", "SMITH").getResultList();
JPQL 쿼리 문자열에서 "Emp"는 엔티티 클래스이고 "ename"은 필드변수명입니다. EntityManager의 createQuery 메소드의 파라미터로 JPQL 쿼리 구문과 대상 엔티티 클래스를 설정합니다. 메소드 체이닝 방식으로 연결해서 사용하는setParameter() 메소드의 파라미터로 위치 보유자 ":ename"에 "SMITH" 문자열을 대입하는 설정입니다. 돌려 받고자 하는 자료형에 따라 질의 실행 메소드 중 getResultList 를 선택해서 사용하고 있습니다.
쿼리문은 단순한 문자열이므로 이 시점에서 "Emp" 엔티티 클래스명을 사용하지 않고 테이블명 "emp"를 사용해도 컴파일 타임에서는 에러가 발견되지 않습니다. 이러한 문제를 해결하기 위해서 Criteria 기술이 등장했습니다.
2.2.2. Criteria
JPQL을 메소드 기반으로 작성할 수 있도록 도와주는 API로 JPQL을 생성하는 빌더입니다. 사용하기 복잡하여 잘 사용되지 않고 있습니다. 이는 대체 기술인 Querydsl이 존재하기 때문입니다.
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<Emp> query = cb.createQuery(Emp.class);
Root<Emp> e = query.from(Emp.class);
CriteriaQuery<Emp> cq = query.select(e).where(cb.equals(e.get("ename"),"SMITH"));
List<Emp> result = em.createQuery(cq).getResultList();
크리테리아 기술은 잘 사용되지 않으므로 간단하게 샘플만 살펴보고 넘어가도록 하겠습니다.
SQL인 "select * fromm emp where ename='SMITH'" 구문을 메소드로 작성하고 있습니다. 보시는 것처럼 간단한 쿼리인데도 코드는 한 눈에 파악하기가 힘듭니다.
우리에게는 이를 대체하는 보다 편리한 기술인 Querydsl이 있으므로 크리테리아는 더 살펴보지 않고 넘어 가겠습니다.
2.2.3. Native SQL
JPQL 을 사용하지 않고 데이터베이스가 이해하는 SQL 쿼리를 개발자가 직접 작성해서 사용하는 방식입니다. JPA에서 지원하지 않는 쿼리를 사용해야 할 때 SQL구문을 직접 작성해서 사용해야 할 경우가 있을 수 있습니다. 예를 들어 오라클의 계층형 쿼리와 같이 DB에 의존적인 쿼리를 작성할 때가 그러한 경우입니다. JPQL과 구분하기 위해서 개발자가 직접 SQL을 작성해서 엔티티매니저에게 주고 사용하는 방식을 Native SQL을 사용한다고 표현합니다.
Native SQL 사용 예
public List<Emp> getEmp1(String ename) {
String sql = "select * from emp where ename='" + ename + "'";
Query query = em.createNativeQuery(sql, Emp.class);
@SuppressWarnings("unchecked")
List<Emp> emps = query.getResultList();
return emps;
}
@Test
public void testGetEmp1() {
List<Emp> emps = dao.getEmp1("SMITH");
for (Emp emp : emps) {
System.out.println(emp);
}
}
createQuery 메소드 대신 createNativeQuery 메소드를 사용하고 있기 때문에 쿼리 구문에서 사용한 "emp"는 데이터베이스에 정의된 테이블명이고 "ename"은 칼럼명이어야 합니다.
엔티티 클래스를 파라미터로 전달하지 않고 처리하는 예제입니다.
public List<Object[]> getEmp2() {
String sql = "select e.ename, e.sal from emp e";
Query query = em.createNativeQuery(sql);
@SuppressWarnings("unchecked")
List<Object[]> result = query.getResultList();
return result;
}
@Test
public void testGetEmp2() {
List<Object[]> result = dao.getEmp2();
for (Object[] row : result) {
System.out.println("name = " + row[0] + ", salary = " + row[1]);
}
}
엔티티 클래스를 파라미터로 전달하지 않았기 때문에 결과를 List<Emp>로 받을 수 없습니다. 이 경우 List<Object[]>로 결과를 받아서 처리해야 합니다.
인덱스기반 위치 지정자 '?'에 파라미터를 대입하여 쿼리를 완성하는 예제입니다.
public List<Object[]> getEmp3(String job) {
String sql = "select e.ename, e.sal from emp e where e.job=?";
Query query = em.createNativeQuery(sql);
query.setParameter(1, job);
@SuppressWarnings("unchecked")
List<Object[]> result = query.getResultList();
return result;
}
@Test
public void testGetEmp3() {
List<Object[]> result = dao.getEmp3("CLERK");
for (Object[] row : result) {
System.out.println("name = " + row[0] + ", salary = " + row[1]);
}
}
네임드 위치 지정자 기호 ':'를 사용하여 파라미터를 대입하여 쿼리를 완성하는 예제입니다.
public List<Object[]> getEmp4(String job) {
String sql = "select e.ename, e.sal from emp e where e.job=:job";
Query query = em.createNativeQuery(sql);
query.setParameter("job", job);
@SuppressWarnings("unchecked")
List<Object[]> result = query.getResultList();
return result;
}
@Test
public void testGetEmp4() {
List<Object[]> result = dao.getEmp4("CLERK");
for (Object[] row : result) {
System.out.println("name = " + row[0] + ", salary = " + row[1]);
}
}
결과 매핑이 복잡한 경우 @SqlResultSetMaping 어노테이션을 이용하여 엔티티에 결과 매핑을 정의해 놓고 사용하는 것이 편리합니다.
다음은 사용 예제입니다.
@SqlResultSetMapping(
name = "empResults",
entities = {
@EntityResult(
entityClass = Emp.class,
fields = {
@FieldResult(name = "empno", column = "empno"),
@FieldResult(name = "ename", column = "ename"),
@FieldResult(name = "job", column = "job"),
@FieldResult(name = "mgr", column = "mgr"),
@FieldResult(name = "hiredate", column = "hiredate"),
@FieldResult(name = "sal", column = "sal"),
@FieldResult(name = "comm", column = "comm"),
@FieldResult(name = "dept", column = "deptno")
}
)
},
columns = { @ColumnResult(name = "annual_income") })
@Entity
public class Emp {
//... 생략
}
public List<Object[]> getEmp5() {
String sql = "select e.*, e.sal*12 as annual_income from emp e";
Query query = em.createNativeQuery(sql, "empResults");
@SuppressWarnings("unchecked")
List<Object[]> result = query.getResultList();
return result;
}
@Test
public void testGetEmp5() {
List<Object[]> result = dao.getEmp5();
for (Object[] row : result) {
Emp emp = (Emp) row[0];
Double annual_income = (Double) row[1];
System.out.println(emp);
System.out.println("annual_income = " + annual_income);
}
}
2.2.4. Querydsl
Querydsl은 JPA 표준은 아니지만 JPQL을 작성하기 위해서 많이 사용되는 오픈 소스 프레임워크입니다. Criteria처럼 JPQL을 메소드 기반으로 작성할 수 있도록 도와주는 빌더 클래스 모음을 제공합니다.
Spring Data JPA 프로젝트도 QueryDSL을 지원하고 있습니다. JPAQuery, JPAQueryFactory를 이용하여 객체지향 쿼리를 작성할 수 있고 JPASQLQuery, SQLQuery, SQLQueryFactory 클래스를 이용하여 엔티티 없이 SQL쿼리를 직접 작성하는 것도 가능합니다. 쿼리 타입(Query Type) 클래스를 먼저 만들고 질의를 위한 메타정보로 사용하여 개발자가 질의 메소드를 작성할 때 보다 간단하게 작성할 수 있도록 도와주는 기술입니다. JPA, JDO, MongoDB, Java Collection, Hibernate Search등에서 지원하며 Spring Data JPA 프로젝트에서 지원하는 오픈소스 프로젝트 입니다.
Querydsl은 JDK 6.0 이상에서 동작합니다. Querydsl에 대한 자세한 내용은 3장부터 살펴봅니다.
2.2.5. 기타 데이터베이스 처리기술
JPA와 함께 Spring JDBC, MyBatis와 같은 기타 데이터베이스 처리기술을 병행해서 사용하는 것도 가능합니다. 일반적으로 신규프로젝트는 여러 기술을 병행 적용해서 개발하지 않지만 기존 프로젝트를 조금씩 업그레이드해 나갈 때는 병행해서 사용해야 하는 필요성이 생길 수 있습니다.
#JPA, #엔티티매니저, #EntityManager, #JPAAuery, #Querydsl, #자바학원, #스프링학원, #SQL학원, #자바교육, #스프링교육, #자바교육, JPA, 엔티티매니저, EntityManager, JPAAuery, Querydsl, 자바학원, 스프링학원, SQL학원, 자바교육, 스프링교육, 자바교육,



