스프링부트, Spring JDBC, MySQL, 모델, Persistence Layer, Service Layer, 자바학원, JAVA학원, 스프링학원, Spring학원
https://www.youtube.com/watch?v=K5R8FOYo34I&list=PLxU-iZCqT52Bihgf3v1bg5xEYeCwFQ_Zz&index=9

https://www.youtube.com/watch?v=jDhjfRRbB9M&list=PLxU-iZCqT52Bihgf3v1bg5xEYeCwFQ_Zz&index=10

http://ojc.asia/bbs/board.php?bo_table=LecSpring&wr_id=901
ojc.asia
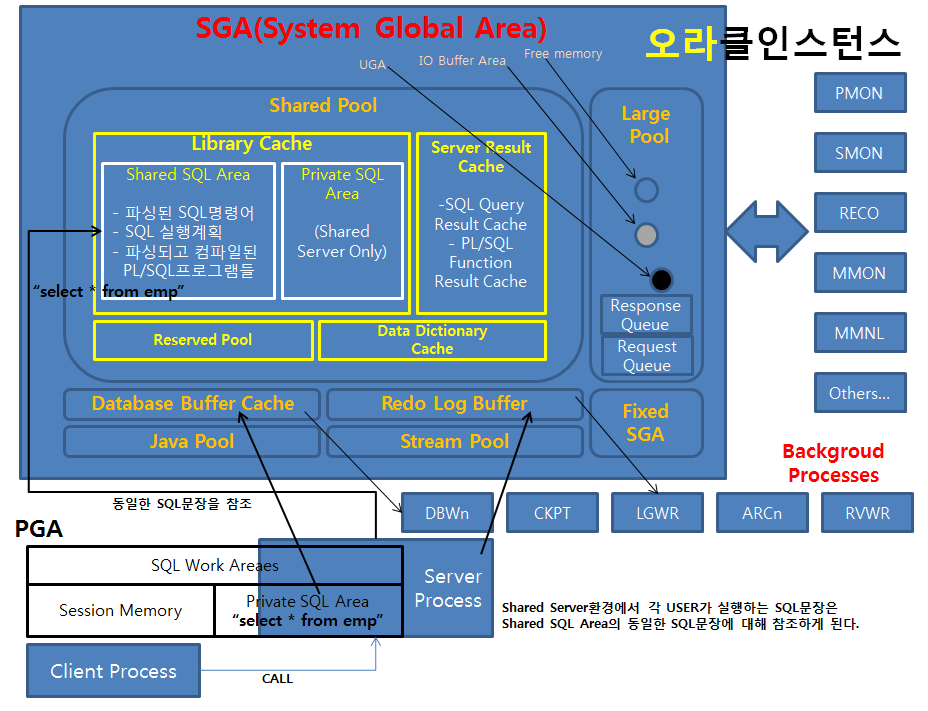
1.2.2. Spring JDBC
현대의 대부분의 비즈니스 프로그램은 데이터베이스와 대화해야 합니다. 따라서 데이터베이스 처리 로직은 애플리케이션의 핵심기능이라 할 수 있습니다.
먼저 데이터베이스 처리기술로 Spring JDBC를 살펴보겠습니다.
Spring JDBC는 자바표준 데이터베이스 처리기술인 JDBC를 개발자가 직접 사용할 경우 처리해야 하는 반복적인 작업을 스프링이 대신 처리해 주는 기술로 개발자를 지루함의 어둠으로부터 꺼내주는 유용한 기술입니다.
직원정보를 갖고 있는 테이블에 질의해서 데이터를 구한 다음 그 결과를 브라우저에게 전달하는 기능을 추가하겠습니다.
새 프로젝트 생성
File > New > Spring Starter Project >
프로젝트 명: chapter1-2 > Next >
디펜던시 선택: Web, JDBC, MySQL > Finish

| 디펜던시 | 용도 |
| Web | 웹 서비스를 구축하기 위해 사용한다. 스프링 핵심 모듈이 대부분 포함되어 있다. |
| JDBC | Spring JDBC 기술을 사용하기 위해 필요하다. |
| MySQL | MySQL 계열에 MariaDB와 연동하기 위한 연결 드라이버이다. |
프로젝트 환경설정
데이터베이스 연결정보를 환경설정 파일에 추가합니다.
application.properties
# DATASOURCE
spring.datasource.platform=mariadb
spring.datasource.sqlScriptEncoding=UTF-8
spring.datasource.url=jdbc:mysql://localhost:3306/testdb?createDatabaseIfNotExist=true
spring.datasource.username=root
spring.datasource.password=1111
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.platform 설정은 필수는 아니지만 스프링 부트에서 SQL의 DDL과 DML을 자동생성 하기위한schema-${platform}.sql, data-${platform}.sql 파일들을 사용할 수 있도록 해주기 때문에 여러 데이터베이스를 사용하는 개발 환경인 경우 설정해 놓으면 편리합니다.
테스트 DB 생성
Maria DB를 설치하면 자동으로 test라는 DB는 존재하지만 testdb라는 DB는 없습니다. 테스트 DB는 "부록 3. HeidiSQL"을 참고하여 데이터베이스에 직접 접속하여 미리 생성해 놓아도 되고, 설정에서 "createDatabaseIfNotExist=true"라고 추가해 놓고 연결시도 시 생성하면서 사용하는 것도 가능합니다.
테스트 테이블 및 테스트 데이터를 입력해 놓기 위해서 application.properties 파일이 위치해 있는 src/main/resources 폴더에 다음 파일들을 생성합니다.
"부록 7.3.4"를 참조하여 파일 내용을 작성합니다.
schema.sql
data.sql
스프링 부트는 기동 시 위 파일들을 발견하면 schema.sql 파일의 DDL쿼리를 실행하고 다음으로 data.sql의 DML쿼리를 수행합니다.
스캐폴딩
프로젝트의 구조를 스캐폴딩(Scaffolding)이라고 부릅니다. 다음 그림을 보고 패키지 및 폴더를 생성합니다. com.example.employee 패키지 밑으로 하부 패키지 및 클래스를 생성하세요.
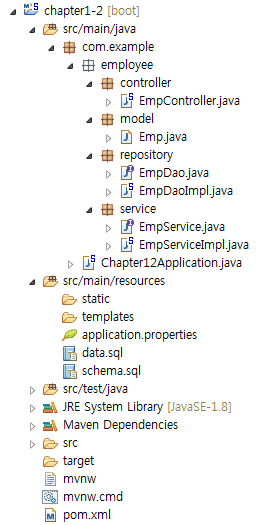
모델 클래스
Value Object 역할을 수행할 모델 클래스를 작성합니다.
Emp.java
package com.example.employee.model;
public class Emp {
private int empno;
private String ename;
private String job;
public Emp() {}
public Emp(int empno, String ename, String job) {
this.empno = empno;
this.ename = ename;
this.job = job;
}
// getter, setter 생략
}
모델 클래스는 데이터베이스의 테이블과 1:1 대응되는 관계입니다. 테이블 내 한 줄의 데이터들을 객체에서 취급하기 위한 일종의 Value Object입니다. 때때로 취급하는 데이터의 개수가 다른 경우 별도의 DTO 클래스를 추가로 사용하기도 합니다.
자바빈 규약에 따라 클래스의 필드변수는 private 접근제어자를 두고 getter, setter 메소드를 제공하는 형태로 작성합니다. 이러한 클래스를 계속 만들다 보면 단순하고 반복적인 작업을 계속하고 있다고 생각하게 됩니다. 이 부분에서 Lombok이 제공하는 기술을 사용하면 개발자는 필드변수만 선언하고 생성자, getter, setter 메소드를 만드는 작업은 롬복이 대신 처리하게 할 수 있습니다. 자세한 사용법은 "부록 4. Lombok"을 참고하세요.
Persistence Layer
데이터베이스와 대화하는 로직을 취급하는 클래스를 작성합니다.
EmpDao.java
package com.example.employee.repository;
import java.util.List;
import com.example.employee.model.Emp;
public interface EmpDao {
public List<Emp> select();
}
경험으로 데이터베이스 처리 로직은 자주 변경된다는 것을 알고 있기에 일반적으로 DAO 구현 클래스를 만들기 전에 인터페이스를 작성합니다.
EmpDaoImpl.java
package com.example.employee.repository;
import java.util.List;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Repository;
import com.example.employee.model.Emp;
@Repository
public class EmpDaoImpl implements EmpDao {
private JdbcTemplate jdbcTemplate;
@Autowired
public void setDataSource(DataSource dataSource){
jdbcTemplate = new JdbcTemplate(dataSource);
}
private RowMapper<Emp> rowMapper = (rs, idx)->{
Emp e = new Emp();
e.setEmpno(rs.getInt("empno"));
e.setEname(rs.getString("ename"));
e.setJob(rs.getString("job"));
return e;
};
@Override
public List<Emp> select() {
String sql = "select empno, ename, job from emp order by empno asc";
return jdbcTemplate.query(sql, rowMapper);
}
}
Spring JDBC 기술의 핵심은 반복적이고 뻔한 작업은 스프링이 대신 처리해 준다는 것입니다. 따라서 개발자는 상황에 따라 변하는 부분인 SQL쿼리 작성과 질의결과 처리 부분만 작업합니다.
프로젝트 자바 버전이 1.8이므로 테이블 한 행의 데이터를 모델 객체에 옮겨 담는 바인딩로직을 정의하는 RowMapper 객체는 람다표현식을 사용하여 코드를 줄일 수 있습니다.
Service Layer
EmpService.java
package com.example.employee.service;
import java.util.List;
import com.example.employee.model.Emp;
public interface EmpService {
public List<Emp> select();
}
여기서는 간단하게 하나의 메소드만 만들어 보겠습니다. 다른 메소드들은 하나씩 추가해 가시면서 살펴보시기 바랍니다.
EmpServiceImpl.java
package com.example.employee.service;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.example.employee.model.Emp;
import com.example.employee.repository.EmpDao;
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpDao empDao;
@Override
public List<Emp> select() {
return empDao.select();
}
}
서비스 레이어의 존재 이유를 현재까지 작성한 코드만을 보고 생각해 내기 어렵지만 실제로 서비스를 구축하게 되면 자연스럽게 여러 비즈니스 로직이 필요하게 되고 그에 따라 서비스 레이어에 여러 로직이 추가됩니다. 전자정부 표준프레임워크에서도 퍼시스턴스 레이어와 서비스 레이어에는 항상 인터페이스를 두고 개발하기를 권고하고 있습니다. 이는 많은 개발자들이 수많은 프로젝트를 수행하면서 인터페이스를 두고 개발하는 것이 좋다는 결론에 동의한 결과라고 볼 수 있습니다.
일반적으로 트랜잭션은 서비스 클래스에 어노테이션으로 설정합니다. 그래야 비즈니스 로직에 따른 여러 쿼리들을 하나의 단위로 처리할 수 있기 때문입니다. 스프링 부트로 프로젝트를 만들고 디펜던시로 JDBC나 JPA를 추가하면 트랜잭션 객체가 빈으로 등록되어 있어서 @Transactional 어노테이션을 서비스 클래스에 추가하기만 하면 클래스 내 모든 메소드에 트랜잭션이 적용됩니다.
Presentation Layer
프리젠테이션 레이어의 임무는 받은 데이터를 예쁘게 만들어 클라이언트에게 전달하는 것입니다.
EmpController.java
package com.example.employee.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import com.example.employee.service.EmpService;
@RestController
public class EmpRestController {
@Autowired
private EmpService empService;
@GetMapping("/emps")
public Object getEmps(){
return empService.select();
}
}
@GetMapping 어노테이션은 @RequestMapping(method={GET}) 어노테이션과 같은 의미를 갖는 편의성 어노테이션입니다. empService.select 메소드의 호출결과는 List<Emp> 객체입니다. 스프링은 RestController 클래스안에 메소드가 객체를 리턴하면 Jackson 라이브러리를 사용하여 JSON 문자열로 변경하고 그 결과를 클라이언트에게 전달합니다.
spring-boot-starter-web 디펜던시를 설정하면 jackson 라이브러리가 추가됩니다.

테스트
http://localhost:8080/emps 주소로 서버에 접속합니다. 총 14건의 Emp 객체가 JSON 포맷의 문자열로 표시됩니다. 참고로 사용하고 있는 테스트 데이터는 오라클 데이터베이스를 설치하면 자동으로 추가되는 SCOTT 계정의 테스트 데이터를 사용하고 있습니다.
다음 그림은 지면을 아끼기 위해서 상위 2건만 표시하고 있습니다.
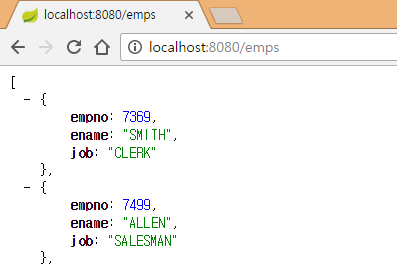
정리
서비스 레이어인 EmpService.java, EmpServiceImpl.java는 비즈니스 로직이 없고 미래에도 없을 거라고 판단된다면 작성하지 않아도 됩니다. 그렇게 본다면 Spring JDBC 기술을 사용할 때 개발자가 처리해야 하는 업무와 순서는 다음과 같습니다.
- pom.xml
프로젝트에서 사용하는 디펜던시를 설정한다.
- application.properties
데이터베이스 연결정보를 설정한다.
- Emp.java
테이블의 1 Row를 자바 객체의 1 Object로 취급하는 용도의 모델 클래스를 만든다.
- EmpDao.java, EmpDaoImpl.java
데이터베이스 처리로직을 갖고 있는 DAO 클래스를 작성한다.
- EmpRestController.java
사용자의 URL 요청을 받아서 결과를 돌려주는 기능을 수행하는 컨트롤러 클래스를 생성한다. 필요하다면 JSP를 별도로 사용하여 최종 결과로 HTML을 클라이언트에 전달할 수 있다.
여러 개의 파일을 역할에 따라 체계적으로 만든 후 연동해서 처리합니다. 사실 대부분의 작업은 미래를 위한 일종의 투자였습니다. 로직이 추가되거나 변화될 것을 대비해서 미리 예비 작업을 수행했다고 볼 수 있습니다.
데이터베이스와 대화하는 로직을 갖고 있는 EmpDaoImpl 클래스의 메소드를 살펴보면 코드는 두줄에 불과합니다. 이는 스프링이 반복적으로 사용되는 JDBC의 Connection. Statement, ResultSet 객체들을 대신 처리해 주기 때문에 가능합니다.
더불어 스프링은 체크드 예외를 언체크드 예외로 전환해서 던져주기 때문에 의미없는 try 구문을 개발자가 매번 코딩할 필요도 없습니다. 하지만 데이터베이스 로직만을 개발해서 다른 개발자에게 제공하는 경우에는 사용의 오용을 방지하기 위해서 try구문이 필요할 수도 있습니다. 이런 경우 여러 데이터베이스가 제 각각 던지는 예외를 일관된 예외로 변경해서 돌려 주는 스프링의 예외전환 서비스의 혜택을 누릴 수 있습니다.
#스프링부트, #스프링JDBC, #SpringJDBC, #스프링교육, #스프링동영상, #자바동영상, #자바교육, #스프링학원, #자바학원, 스프링부트, 스프링JDBC, SpringJDBC, 스프링교육, 스프링동영상, 자바동영상, 자바교육, 스프링학원, 자바학원,