스프링교육학원/자바학원)SpringJPA,Querydsl 오라클 SQL 쿼리, 오라클Rownum, With문, 시퀀스, Union, NVL, NVL2, DECODE, Rank, 계층형쿼리,오라클힌트, 오라클함수, 프로시저
Querydsl 오라클 SQL 쿼리실습예제, Oracle Rownum, With문, Sequence, Union, NVL, NVL2, DECODE, Rank, 계층형쿼리, 오라클힌트, 프러시저, 함수6장. Querydsl SQL 쿼리 with Oracle 오라클데이터베이스는 사용자 수 1위인 대표적인 관계형 데이터베이스입니다. 그만큼 오라클에서만 사용가능한…
ojc.asia


6장. Querydsl SQL 쿼리 with Oracle
오라클데이터베이스는 사용자 수 1위인 대표적인 관계형 데이터베이스입니다. 그만큼 오라클에서만 사용가능한 SQL 방법들이 많이 존재합니다. 이번 장에서 Querydsl을 사용하여 이러한 것들을 어떻게 메소드 기반으로 작성할 수 있는지 살펴보겠습니다.
6.1. 테스트 프로젝트 만들기
개발을 위한 프로젝트 생성 및 환경설정 자체도 연습이 필요한 부분이므로 다음 내용을 따라서 진행하시는 것을 권해 드립니다. 하지만 "부록 7.4 Querydsl SQL Query with Oracle"을 참조하여 진행하셔도 괜찮습니다.
6.1.1. 프로젝트 생성
File > New > Spring Starter Project >
프로젝트 명: chapter6-1 > Next >
디펜던시 선택: Web, JPA, Lombok > Finish
6.1.2. 데이터베이스 및 테이블 생성
"부록 5. Oracle Database"를 참조하여 오라클 데이터베이스를 설치합니다.
1. DB 생성
데이터베이스 설치 시 이미 생성되어 있는 SCOTT 계정의 DB를 사용합니다.
2. 테이블 생성
데이터베이스 설치 시 이미 생성되어 있는 테스트 테이블들을 대상으로 학습합니다.
DEPT, EMP, SALGRADE
3. 테스트 더미 데이터 입력
데이터베이스 설치 시 이미 테스트 용도로 입력되어 있는 정보를 그대로 사용하여 학습합니다.
필요하다면 다음 쿼리를 사용하여 초기화 하십시오.
dept-emp-salgrade-ddl.sql
DROP TABLE EMP;
DROP TABLE DEPT;
DROP TABLE SALGRADE;
CREATE TABLE DEPT(
DEPTNO NUMBER(2) CONSTRAINT PK_DEPT PRIMARY KEY,
DNAME VARCHAR2(14),
LOC VARCHAR2(13)
);
CREATE TABLE EMP(
EMPNO NUMBER(4) CONSTRAINT PK_EMP PRIMARY KEY,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) CONSTRAINT FK_DEPTNO REFERENCES DEPT
);
CREATE TABLE SALGRADE(
GRADE NUMBER,
LOSAL NUMBER,
HISAL NUMBER
);
INSERT INTO DEPT VALUES (10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES (20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES (30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES (40,'OPERATIONS','BOSTON');
INSERT INTO EMP VALUES(7369,'SMITH','CLERK', 7902,
to_date('17-12-1980','dd-mm-yyyy'),800,NULL,20);
INSERT INTO EMP VALUES(7499,'ALLEN','SALESMAN', 7698,
to_date('20-2-1981', 'dd-mm-yyyy'),1600,300,30);
INSERT INTO EMP VALUES(7521,'WARD','SALESMAN', 7698,
to_date('22-2-1981', 'dd-mm-yyyy'),1250,500,30);
INSERT INTO EMP VALUES(7566,'JONES','MANAGER', 7839,
to_date('2-4-1981', 'dd-mm-yyyy'),2975,NULL,20);
INSERT INTO EMP VALUES(7654,'MARTIN','SALESMAN',7698,
to_date('28-9-1981', 'dd-mm-yyyy'),1250,1400,30);
INSERT INTO EMP VALUES(7698,'BLAKE','MANAGER', 7839,
to_date('1-5-1981', 'dd-mm-yyyy'),2850,NULL,30);
INSERT INTO EMP VALUES(7782,'CLARK','MANAGER', 7839,
to_date('9-6-1981', 'dd-mm-yyyy'),2450,NULL,10);
INSERT INTO EMP VALUES(7788,'SCOTT','ANALYST', 7566,
to_date('13-07-1987', 'dd-mm-yyyy'),3000,NULL,20);
INSERT INTO EMP VALUES(7839,'KING','PRESIDENT', NULL,
to_date('17-11-1981','dd-mm-yyyy'),5000,NULL,10);
INSERT INTO EMP VALUES(7844,'TURNER','SALESMAN',7698,
to_date('8-9-1981', 'dd-mm-yyyy'),1500,0,30);
INSERT INTO EMP VALUES(7876,'ADAMS','CLERK', 7788,
to_date('13-07-1987', 'dd-mm-yyyy'),1100,NULL,20);
INSERT INTO EMP VALUES(7900,'JAMES','CLERK', 7698,
to_date('3-12-1981', 'dd-mm-yyyy'),950,NULL,30);
INSERT INTO EMP VALUES(7902,'FORD','ANALYST', 7566,
to_date('3-12-1981', 'dd-mm-yyyy'),3000,NULL,20);
INSERT INTO EMP VALUES(7934,'MILLER','CLERK', 7782,
to_date('23-1-1982', 'dd-mm-yyyy'),1300,NULL,10);
INSERT INTO SALGRADE VALUES (1, 700,1200);
INSERT INTO SALGRADE VALUES (2,1201,1400);
INSERT INTO SALGRADE VALUES (3,1401,2000);
INSERT INTO SALGRADE VALUES (4,2001,3000);
INSERT INTO SALGRADE VALUES (5,3001,9999);
COMMIT;
6.1.3. 프로젝트 환경설정
logback-spring.xml
이전 프로젝트에서 사용하던 파일을 그대로 사용합니다.
log4jdbc.log4j2.properties
이전 프로젝트에서 사용하던 파일을 그대로 사용합니다.
application.properties
# DATASOURCE
spring.datasource.platform=oracle
spring.datasource.sqlScriptEncoding=UTF-8
spring.datasource.url=jdbc:log4jdbc:oracle:thin:@192.168.0.225:1521:orcl
spring.datasource.username=sccott
spring.datasource.password=1234
spring.datasource.driver-class-name=net.sf.log4jdbc.sql.jdbcapi.DriverSpy
# ignore schema.sql, data.sql
spring.datasource.initialize=false
# JPA
spring.jpa.hibernate.ddl-auto=none
spring.jpa.database-platform=org.hibernate.dialect.Oracle10gDialect
spring.jpa.show-sql=true
spring.data.jpa.repositories.enabled=true
# Logging
logging.config=classpath:logback-spring.xml
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>boot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.1.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<querydsl.version>4.1.2</querydsl.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.bgee.log4jdbc-log4j2</groupId>
<artifactId>log4jdbc-log4j2-jdbc4.1</artifactId>
<version>1.16</version>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>${querydsl.version}</version>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-sql-spring</artifactId>
<version>${querydsl.version}</version>
</dependency>
<!-- for oracle -->
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.1.0.7.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-maven-plugin</artifactId>
<version>${querydsl.version}</version>
<executions>
<execution>
<goals>
<goal>export</goal>
</goals>
</execution>
</executions>
<configuration>
<jdbcDriver>oracle.jdbc.driver.OracleDriver</jdbcDriver>
<jdbcUrl>jdbc:oracle:thin:@192.168.0.225:1521:orcl</jdbcUrl>
<jdbcUser>scott</jdbcUser>
<jdbcPassword>1234</jdbcPassword>
<packageName>jpa.model</packageName>
<exportTable>true</exportTable>
<exportView>false</exportView>
<exportPrimarykey>true</exportPrimarykey>
<!-- schemaPattern을 안쓰면 all_tables로 select할수 있는 모든 테이블이 export됨 -->
<schemaPattern>SCOTT</schemaPattern>
<!-- 테이블 이름을 콤마로 구분해서 패턴을 줄 수 있다. 테이블명을 대문자로 사용할 것-->
<tableNamePattern>DEPT,EMP,SALGRADE</tableNamePattern>
<targetFolder>target/generated-sources/java</targetFolder>
<namePrefix>Q</namePrefix>
<!-- targetFolder에 테이블에 대한 모델 클래스 생성 -->
<exportBeans>false</exportBeans>
</configuration>
<dependencies>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.1.0.7.0</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>oracle</id>
<name>ORACLE JDBC Repository</name>
<url>https://maven.oracle.com;
</repository>
</repositories>
</project>
오라클 드라이버는 Maven 중앙저장소에 없기 때문에 별도의 Repository를 설정해야 합니다.
6.1.4. Q 타입 클래스 생성
프로젝트 선택 > 마우스 오른쪽 클릭 > Run As > Maven generate-sources 클릭

사진 설명을 입력하세요.
QType 클래스가 3개가 생성되었습니다.
6.1.5. SQLQueryFactory 빈 등록
QuerydslConfig.java
package com.example.common.config;
import java.sql.Connection;
import javax.inject.Provider;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import com.querydsl.sql.Configuration;
import com.querydsl.sql.OracleTemplates;
import com.querydsl.sql.SQLQueryFactory;
import com.querydsl.sql.SQLTemplates;
import com.querydsl.sql.spring.SpringConnectionProvider;
import com.querydsl.sql.spring.SpringExceptionTranslator;
@org.springframework.context.annotation.Configuration
public class QuerydslConfig {
@Autowired
private DataSource dataSource;
@Bean
public Configuration configuration() {
SQLTemplates templates = OracleTemplates.builder().build();
Configuration configuration = new Configuration(templates);
configuration.setExceptionTranslator(new SpringExceptionTranslator());
return configuration;
}
@Bean
public SQLQueryFactory queryFactory() {
Provider<Connection> provider = new SpringConnectionProvider(dataSource);
return new SQLQueryFactory(configuration(), provider);
}
}
6.2. Rownum
6.2.1. 상위 로우 구하기
결과처리를 모두 마친 후 자동으로 추가되는 칼럼인 rownum을 사용하는 방법을 살펴봅니다.
목표 쿼리
select empno, ename from emp where rownum <=5
구현 메소드
rownum 처리를 위하여 limit 메소드를 사용합니다.
public List<Tuple> getEmpByRownum() {
List<Tuple> rows = queryFactory
.select(emp.empno, emp.ename)
.from(emp).orderBy(emp.empno.asc())
.limit(5).fetch();
return rows;
}
테스트 메소드
@Autowired
private EmpDaoRownum dao;
QEmp emp = QEmp.emp;
@Test
public void testGetEmpByRownum() {
List<Tuple> rows = dao.getEmpByRownum();
rows.forEach((row)->System.out.println(
row.get(emp.empno) +"," + row.get(emp.ename)));
}
테스트 결과
select * from (
select EMP.EMPNO, EMP.ENAME
from EMP EMP
order by EMP.EMPNO asc
) where rownum <= 5
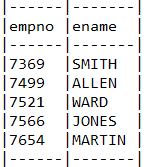
사진 설명을 입력하세요.
6.2.2. 범위 로우 구하기
목표 쿼리
select * from (
select rownum as rnum, e.empno, e.ename from emp e
order by e.empno asc
) where rnum > 1 and rnum < 5;
구현 메소드
offset 메소드로 상단 로우를 출력 범위에서 제거합니다. limit 메소드로 구하고자 하는 로우의 개수를 지정합니다.
public List<Tuple> getEmpByOffsetLimit() {
List<Tuple> rows = queryFactory
.select(emp.empno, emp.ename)
.from(emp).orderBy(emp.empno.asc())
.offset(1).limit(3).fetch();
return rows;
}
테스트 메소드
@Test
public void testGetEmpByOffsetLimit() {
List<Tuple> rows = dao.getEmpByOffsetLimit();
rows.forEach((row)->System.out.println(
row.get(emp.empno) +"," + row.get(emp.ename)));
}
테스트 결과
select * from (
select a.*, rownum rn from (
select
EMP.COMM, EMP.DEPTNO, EMP.EMPNO,
EMP.ENAME, EMP.HIREDATE, EMP.JOB, EMP.MGR, EMP.SAL
from EMP EMP
order by EMP.EMPNO asc
) a
) where rn > 1 and rownum <= 3

사진 설명을 입력하세요.
6.3. With
서브쿼리가 반복되어 사용되는 경우 with 구문을 사용해서 서브쿼리를 독립적으로 지정하고 재 활용하여 사용할 수 있습니다.
목표 쿼리
with employee as (
select deptno, avg(sal) avg_sal
from emp group by deptno)
select dname, employee.avg_sal
from dept inner join employee
on dept.deptno = employee.deptno;
구현 메소드
public List<Tuple> getDeptAvgSal() {
// 서브쿼리를 위해 사용한다.
QEmp e = new QEmp("e");
// with 구문은 별칭을 사용해야 한다.
QEmp employee = new QEmp("employee");
// employee.sal로 표현해야 하기 때문에 월급 평균값의 별칭을 "sal"로 지정해야 한다.
List<Tuple> rows = queryFactory
.query().with(employee, SQLExpressions
.select(e.deptno, e.sal.avg().as("sal"))
.from(e).groupBy(e.deptno))
.select(dept.dname, employee.sal)
.from(dept).innerJoin(employee)
.on(dept.deptno.eq(employee.deptno)).fetch();
return rows;
}
테스트 메소드
@Test
public void testGetDeptAvgSal() {
// 별칭을 사용했으므로 결과를 꺼낼 때도 별칭을 사용한다.
QEmp employee = new QEmp("employee");
List<Tuple> rows = dao.getDeptAvgSal();
rows.forEach((row)->System.out.println(
row.get(dept.dname) +"," + row.get(employee.sal)));
}
테스트 결과
with employee as (
select e.DEPTNO, avg(e.SAL) sal
from EMP e group by e.DEPTNO)
select DEPT.DNAME, employee.SAL
from DEPT DEPT inner join employee employee
on DEPT.DEPTNO = employee.DEPTNO
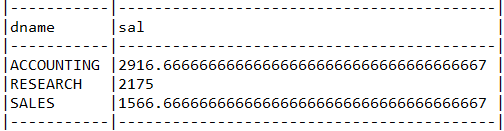
사진 설명을 입력하세요.
6.4. Sequence
테이블과 별도로 존재하면서 값이 순차적으로 증가하는 칼럼을 위해서 사용하는 시퀀스의 설정방법을 살펴봅니다.
시퀀스 생성 쿼리
create sequence test_seq_emp_empno
start with 1 increment by 1
nomaxvalue nominvalue
nocycle nocache ;
사용 메소드
public Long insert(Emp model) {
// 시퀀스이름을 설정할 때 앞에 스키마명까지 사용해야 한다.
Long affected = queryFactory.insert(emp)
.columns(emp.empno, emp.ename, emp.deptno)
.values(SQLExpressions.nextval("SCOTT.test_seq_emp_empno"),
model.getEname(), model.getDeptno()).execute();
return affected;
}
테스트 메소드
@Test
public void testInsert() {
Byte deptno = 40;
Emp model = new Emp();
model.setEname("TESTER");
model.setDeptno(deptno);
Long affected = dao.insert(model);
System.out.println("affected = "+affected);
}
테스트 결과
insert into EMP (EMPNO, ENAME, DEPTNO)
values (SCOTT.test_seq_emp_empno.nextval, 'TESTER', 40)
6.5. Union
두 개 이상의 테이블의 질의 결과를 결합할 때 사용합니다. union만 사용하면 중복된 로우를 제거하고 결과를 구하지만 union all을 사용하면 중복된 로우도 결과에 포함됩니다. union은 중복 로우를 제거하기 위해서 정렬을 수행하며 따라서 union all 보다 느립니다.
목표 쿼리
select empno, ename, deptno, job from emp where job='CLERK'
union all
select empno, ename, deptno, job from emp where deptno=20
구현 메소드
@SuppressWarnings("unchecked")
public List<Tuple> get(String job, Byte deptno){
QEmp e = new QEmp("e");
List<Tuple> rows = queryFactory.query().unionAll(
SQLExpressions.select(emp.empno, emp.ename, emp.deptno, emp.job)
.from(emp).where(emp.job.eq(job)),
SQLExpressions.select(e.empno, e.ename, e.deptno, e.job)
.from(e).where(e.deptno.eq(deptno))).fetch();
return rows;
}
테스트 메소드
@Test
public void testGet() {
String job = "CLERK";
Byte deptno = 20;
List<Tuple> rows = dao.get(job, deptno);
rows.forEach((row)->System.out.println(
row.get(emp.empno) + "," +
row.get(emp.ename) + "," +
row.get(emp.deptno) + "," +
row.get(emp.job)));
}
테스트 결과
(
select EMP.EMPNO, EMP.ENAME, EMP.DEPTNO, EMP.JOB
from EMP EMP where EMP.JOB = 'CLERK'
)
union all
(
select e.EMPNO, e.ENAME, e.DEPTNO, e.JOB
from EMP e where e.DEPTNO = 20
)
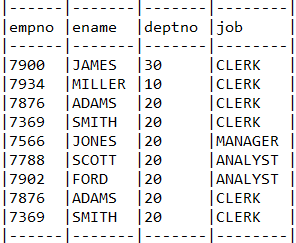
사진 설명을 입력하세요.
6.6. Nvl
결과값이 null일 때 결과값을 변경하기 위해서 사용합니다.
6.6.1. Nvl
목표 쿼리 1
--mgr이 null인 경우 대신 0 값을 리턴한다.
select empno, nvl(mgr, 0) mgr from emp where deptno = 10
목표 쿼리 2
--coalesce 함수는 null이 아닌 첫 값을 사용하므로 mgr이 null인 경우 0 값을 리턴한다.
select empno, coalesce(mgr, 0) mgr from emp where deptno=10
구현 메소드
public List<Tuple> getUsingNvl(Byte deptno){
Short zero = 0;
List<Tuple> rows = queryFactory
.select(emp.empno, emp.mgr.coalesce(zero).as("mgr"))
.from(emp).where(emp.deptno.eq(deptno)).fetch();
return rows;
}
테스트 메소드
@Test
public void testGetUsingNvl() {
Byte deptno = 10;
List<Tuple> rows = dao.getUsingNvl(deptno);
rows.forEach((row)->System.out.println(
row.get(emp.empno) +"," + row.get(emp.mgr)));
}
테스트 결과
select EMP.EMPNO, coalesce(EMP.MGR, 0) mgr
from EMP EMP
where EMP.DEPTNO = 10
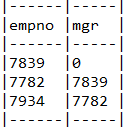
사진 설명을 입력하세요.
6.6.2. Nvl2
Querydsl의 CaseBuilder 클래스를 사용하여 구현할 수 있습니다.
목표 쿼리
--mgr이 null 아닌 경우 1을, null인 경우 0 값을 리턴한다.
select empno, nvl2(mgr, 1, 0) mgr from emp where deptno = 10
구현 메소드
public List<Tuple> getUsingNvl2(Byte deptno){
Expression<Short> nvl2 = new CaseBuilder()
.when(emp.mgr.isNotNull()).then((short) 1)
.otherwise((short) 0).as(emp.mgr);
List<Tuple> rows = queryFactory
.select(emp.empno, nvl2)
.from(emp).where(emp.deptno.eq(deptno)).fetch();
return rows;
}
테스트 메소드
@Test
public void testGetUsingNvl2() {
Byte deptno = 10;
List<Tuple> rows = dao.getUsingNvl2(deptno);
rows.forEach((row)->System.out.println(
row.get(emp.empno) +"," + row.get(emp.mgr)));
}
테스트 결과
select EMP.EMPNO, (
case when EMP.MGR is not null then 1
else 0 end) mgr
from EMP EMP
where EMP.DEPTNO = 10
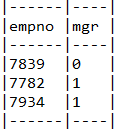
사진 설명을 입력하세요.
6.7. Decode
오라클에서 사용하는 SQL의 DECODE는 CASE문으로 풀어서 쓸 수 있습니다.
Querydsl에서는 CaseBuilder 클래스를 사용합니다.
목표 쿼리
select emp.ename,
decode(emp.deptno,
10, 'ACCOUNTING',
20, 'RESEARCH',
30, 'SALES',
40, 'OPERATIONS',
'UNKNOWN') dname
from emp
구현 메소드
public List<Tuple> get(){
Expression<String> cases = new CaseBuilder()
.when(emp.deptno.eq((byte) 10)).then("ACCOUNTING")
.when(emp.deptno.eq((byte) 20)).then("RESEARCH")
.when(emp.deptno.eq((byte) 30)).then("SALES")
.when(emp.deptno.eq((byte) 40)).then("OPERATIONS")
.otherwise("UNKNOWN").as(dept.dname);
List<Tuple> rows = queryFactory
.select(emp.ename, cases)
.from(emp).fetch();
return rows;
}
앨리어스 설정으로 dept.dname을 사용하지 않고 문자열을 사용하면 Tuple에서 칼럼 데이터를 꺼내기 위해서 인덱스를 사용해야 하는 불편함이 생깁니다.
테스트 메소드
@Test
public void testGet() {
List<Tuple> rows = dao.get();
rows.forEach((row)->System.out.println(
row.get(emp.ename) +"," + row.get(dept.dname)));
}
테스트 결과
select EMP.ENAME, (
case
when EMP.DEPTNO = 10 then 'ACCOUNTING'
when EMP.DEPTNO = 20 then 'RESEARCH'
when EMP.DEPTNO = 30 then 'SALES'
when EMP.DEPTNO = 40 then 'OPERATIONS'
else 'UNKNOWN' end) dname
from EMP EMP
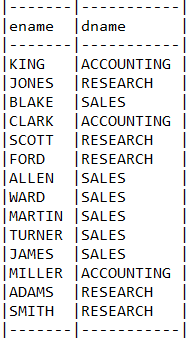
사진 설명을 입력하세요.
6.8. Rank
rank는 결과값을 기준으로 순위를 부여하기 위해서 사용합니다. rank는 1등이 2명인 경우 다음 순위는 3등으로 처리합니다. dense_rank는 1등이 2명인 경우 다음 순위는 2등으로 처리합니다.
목표 쿼리
select
ename, sal, deptno,
rank() over (order by sal desc) sal_rank,
dense_rank() over (partition by deptno order by sal desc) dept_sal_rank
from emp
order by sal_rank asc, dept_sal_rank asc;
구현 메소드
@SuppressWarnings("unchecked")
public List<Tuple> get() {
// 칼럼 별칭으로 정렬하기 위해서 사용한다.
Path<Long> sal_rank = Expressions.numberPath(Long.class, "sal_rank");
Path<Long> dept_sal_rank = Expressions.numberPath(Long.class, "dept_sal_rank");
List<Tuple> rows = queryFactory
.select(emp.ename, emp.sal, emp.deptno,
SQLExpressions.rank().over().orderBy(emp.sal.desc()).as(sal_rank),
SQLExpressions.denseRank().over().partitionBy(emp.deptno)
.orderBy(emp.sal.desc()).as(dept_sal_rank))
.from(emp)
.orderBy(((ComparableExpressionBase<Long>) sal_rank).asc(),
((ComparableExpressionBase<Long>) dept_sal_rank).asc())
.fetch();
return rows;
}
테스트 메소드
@Test
public void testGet() {
// Tuple 객체에 담겨 있는 칼럼 정보를 꺼낼 때 칼럼 별칭을 사용하기 위해서 필요하다.
Path<Long> sal_rank = Expressions.numberPath(Long.class, "sal_rank");
Path<Long> dept_sal_rank = Expressions.numberPath(Long.class, "dept_sal_rank");
List<Tuple> rows = dao.get();
rows.forEach((row)->System.out.println(
row.get(emp.ename) +"," +
row.get(emp.sal) +"," +
row.get(emp.deptno) +"," +
row.get(sal_rank) +"," +
row.get(dept_sal_rank)));
}
테스트 결과
select
EMP.ENAME, EMP.SAL, EMP.DEPTNO,
rank() over (order by EMP.SAL desc) sal_rank,
dense_rank() over (partition by EMP.DEPTNO order by EMP.SAL desc) dept_sal_rank
from EMP EMP
order by sal_rank asc, dept_sal_rank asc
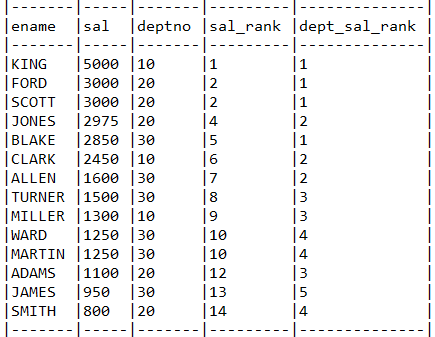
사진 설명을 입력하세요.
6.9. Hierarchical Queries, Hint
6.9.1. 프로젝트 생성
앞서 만든 chapter6-1 프로젝트를 선택한 후 ctrl+c > ctrl+v를 눌러서 소스 전체를 복사해서 프로젝트 명을 chapter6-9라고 명명하고 생성합니다.
6.9.2. 계층형 쿼리
EMP 테이블에서 KING으로부터 시작하여 계층적으로 출력하는 계층쿼리를 살펴보겠습니다. 오라클의 계층형쿼리를 사용하려면 OracleQuery를 사용하고 LEVEL과 같은 의사칼럼은 OracleGrammar를 쓰면 됩니다.
물론 ROWID, ROWNUM, SYSDATE등도 OracleGrammar에서 지원합니다.
원래 만들고자 했던 오라클 계층 쿼리
select
lpad(' ',(level-1)*2) || ename, sal
from emp
start with ename = 'KING'
connect by prior empno = mgr
querydsl의 OracleQuery를 통해 생성된 SQL
select
lpad(' ',(level - 1) * 2) || EMP.ENAME, EMP.SAL
from EMP EMP
start with EMP.ENAME = 'KING'
connect by prior EMP.EMPNO = EMP.MGR
Querydsl을 사용하여 메소드기반으로 쿼리를 작성해도 원하는 오라클 전용 쿼리를 작성할 수 있음을 알 수 있습니다.
QuerydslRepository.java
package com.example.employee.repository;
import java.util.List;
import com.querydsl.core.Tuple;
public interface QuerydslRepository {
// EMP 테이블에서 KING에서부터 시작하여 계층적으로 출력하는 계층쿼리
List<Tuple> getHQuery() throws Exception;
// EMP, DEPT을 DEPTNO로 조인하여 SAL 내림차순 정렬, 5건 출력(힌트 안 쓴것)
// 인라인뷰, 조인 예문
List<Tuple> getEnameDnameSalDesc();
// EMP, DEPT을 DEPTNO로 조인하여 SAL 내림차순 정렬, 5건 출력(힌트 쓴것)
// 인라인뷰, 조인, 힌트예문
List<Tuple> getEnameDnameSalDesc2();
}
QuerydslRepositoryImpl.java
package com.example.employee.repository;
import static com.example.employee.model.QEmp.emp;
import static com.example.employee.model.QDept.dept;
import java.util.List;
import javax.sql.DataSource;
import javax.transaction.Transactional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import com.example.employee.model.QDept;
import com.example.employee.model.QEmp;
import com.querydsl.core.QueryFlag;
import com.querydsl.core.Tuple;
import com.querydsl.core.types.dsl.Expressions;
import com.querydsl.core.types.dsl.StringExpression;
import com.querydsl.core.types.dsl.StringExpressions;
import com.querydsl.sql.Configuration;
import com.querydsl.sql.SQLExpressions;
import com.querydsl.sql.SQLQueryFactory;
import com.querydsl.sql.oracle.OracleGrammar;
import com.querydsl.sql.oracle.OracleQuery;
@Repository
@Transactional
public class QuerydslRepositoryImpl implements QuerydslRepository {
@Autowired
SQLQueryFactory queryFactory;
@Autowired
DataSource dataSource;
@Autowired
Configuration configuration;
@SuppressWarnings("unchecked")
@Override
public List<Tuple> getHQuery() throws Exception {
@SuppressWarnings("rawtypes")
OracleQuery query = new OracleQuery(
dataSource.getConnection(), configuration);
List<Tuple> rows = query
.select(
StringExpressions.lpad(
Expressions.stringTemplate("' '").stringValue(),
OracleGrammar.level.subtract(1).multiply(2)
).concat(emp.ename).as("ename"),
emp.sal)
.startWith(emp.ename.eq("KING"))
.connectByPrior(emp.empno.eq(emp.mgr))
.from(emp).fetch();
return rows;
}
}
출력 로그
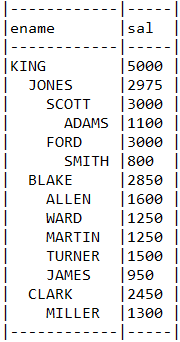
사진 설명을 입력하세요.
6.9.3. 힌트
EMP, DEPT을 DEPTNO로 조인합니다. SAL 칼럼으로 내림차순 정렬하여 5건을 출력합니다.
limit 메소드 또는 OracleGrammar의 ROWNUM을 사용합니다.
힌트를 적용하지 않은 예제
예상쿼리
SELECT *
FROM (
SELECT E.ENAME, D.DNAME, E.SAL
FROM (SELECT ENAME, SAL, DEPTNO FROM MYEMP1) E,
MYDEPT1 D
WHERE E.DEPTNO = D.DEPTNO
ORDER BY SAL DESC
)
WHERE ROWNUM <= 5;
Querydsl로 만든 쿼리
select * from (
select ename, dname, sal
from (select MYEMP1.ENAME ename, MYDEPT1.DNAME dname, MYEMP1.SAL sal
from MYEMP1 MYEMP1
inner join MYDEPT1 MYDEPT1
on MYEMP1.DEPTNO = MYDEPT1.DEPTNO
order by MYEMP1.SAL desc)
) where rownum <= 5
QuerydslRepositoryImpl.java
@Override
public List<Tuple> getEnameDnameSalDesc() {
// 아래 query를 stringTemplates으로 만들면 select 'ename', 'dname','sal' 형태의
// 쿼리가 생성되니 주의할 것
StringExpression query1 = Expressions.stringPath("ename");
StringExpression query2 = Expressions.stringPath("dname");
StringExpression query3 = Expressions.stringPath("sal");
QEmp myemp1 = new QEmp("myemp1");
QDept mydept1 = new QDept("mydept1");
List<Tuple> rows = queryFactory
.select(query1, query2,
query3)
.from(SQLExpressions
.select(myemp1.ename.as("ename"),
mydept1.dname.as("dname"),
myemp1.sal.as("sal"))
.from(myemp1)
.innerJoin(mydept1)
.on(myemp1.deptno.eq(mydept1.deptno))
.orderBy(myemp1.sal.desc()))
.limit(5).fetch();
return rows;
}
실행계획
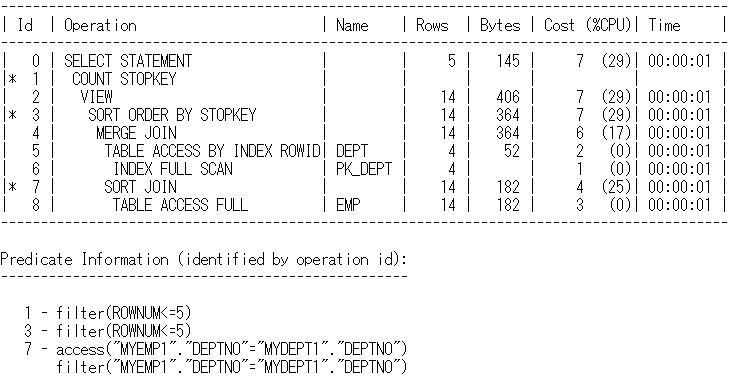
사진 설명을 입력하세요.
힌트를 적용한 예제
getEnameDnameSalDesc()에서 사용된 order by절을 빼고 오라클 힌트를 사용하여 쿼리를 튜닝합니다. EMP, DEPT을 DEPTNO로 조인합니다. SAL칼럼으로 내림차순 정렬하여 5건을 출력합니다.
예상 쿼리
SELECT * FROM (
SELECT /*+ index_desc(MYEMP1 idx_myemp1_sal) */
MYEMP1.ENAME, MYDEPT1.DNAME, MYEMP1.SAL
FROM (SELECT ENAME, SAL, DEPTNO
FROM MYEMP1) MYEMP1,
MYDEPT1
WHERE MYEMP1.DEPTNO = MYDEPT1.DEPTNO
AND MYEMP1.SAL > 0
)
WHERE ROWNUM <= 5;
Querydsl로 만든 쿼리
select * from (
select ename, dname, sal
from (select /*+ index_desc(MYEMP1 idx_myemp1_sal) */
MYEMP1.ENAME ename, MYDEPT1.DNAME dname, MYEMP1.SAL sal
from MYEMP1 MYEMP1
inner join MYDEPT1 MYDEPT1
on MYEMP1.DEPTNO = MYDEPT1.DEPTNO
and MYEMP1.SAL > 0)
) where rownum <= 5
QuerydslRepositoryImpl.java
@Override
public List<Tuple> getEnameDnameSalDesc2() {
StringExpression query1 = Expressions.stringPath("ename");
StringExpression query2 = Expressions.stringPath("dname");
StringExpression query3 = Expressions.stringPath("sal");
QEmp myemp1 = new QEmp("myemp1");
QDept mydept1 = new QDept("mydept1");
List<Tuple> rows = queryFactory
.select(query1, query2, query3)
.from(SQLExpressions
.select(myemp1.ename.as("ename"),
mydept1.dname.as("dname"),
myemp1.sal.as("sal"))
.addFlag(QueryFlag.Position.AFTER_SELECT,
"/*+ index_desc(MYEMP1 idx_myemp1_sal) */")
.from(myemp1)
.innerJoin(mydept1)
.on(myemp1.deptno.eq(mydept1.deptno)
.and(myemp1.sal.gt(0))
))
.limit(5).fetch();
return rows;
}
실행계획
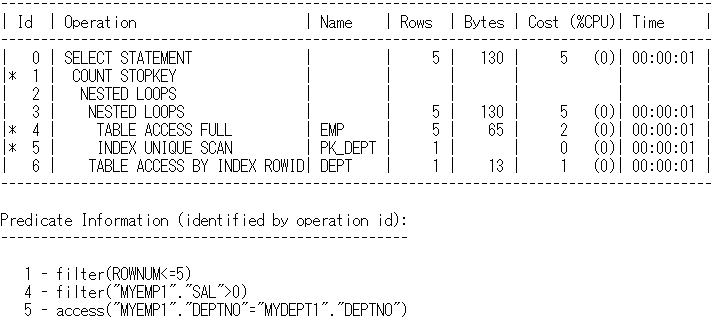
사진 설명을 입력하세요.
힌트를 적용하여 쿼리의 퍼포먼스를 높였음을 알 수 있습니다.
6.10. Procedure
오라클의 프로시저와 연동하는 방법을 살펴보겠습니다. 프로시저와 연동하는 가장 간편한 방법은 Spring Data JPA가 제공하는 기능을 이용하는 것입니다.
6.10.1. 프로젝트 생성
앞서 만든 chapter6-1 프로젝트를 선택한 후 ctrl+c > ctrl+v를 눌러서 소스 전체를 복사해서 프로젝트 명을 chapter6-10라고 명명하고 생성합니다.
6.10.2. 오라클 프로시져
학습을 위해 사용할 프로시저를 데이터베이스에 접속하여 생성합니다.
p_ getEnameByEmpno
CREATE OR REPLACE PROCEDURE p_getEnameByEmpno(
p_empno IN INTEGER, p_ename OUT VARCHAR2)
IS
BEGIN
SELECT ename INTO p_ename FROM emp WHERE empno=p_empno;
END;
/
p_getEmpByDeptno
CREATE OR REPLACE PROCEDURE p_getEmpByDeptno(
p_deptno IN INTEGER, emp_cursor OUT SYS_REFCURSOR)
IS
sql_string Varchar2(400);
BEGIN
sql_string:='select empno, ename, deptno from emp where deptno=:deptno';
Open emp_cursor FOR sql_string USING p_deptno;
END;
/
6.10.3. @NamedStoredProcedureQuery, @Procedure
@StoredProcedureParameter의 name속성으로 DB에 만든 프로시저의 파라미터명을 사용할 수 있지만 out parameter와 같이 사용되는 경우에는 사용이 불가능 합니다. out parameter와 사용하는 경우 프로시저의 파라미터 사용은 위치지정 방식으로 사용해야 합니다. 또한 위치 지정방식과 Named 방식은 혼재해서 사용할 수 없습니다.
참조: https://hibernate.atlassian.net/browse/HHH-10756
Spring Data JPA의 Hibernate는 REF_CURSOR를 지원하지 않지만 EclipseLink는 지원합니다.
REF CURSOR를 사용하는 경우 Spring Data JPA에서 지원하지 않으므로 직접 구현해서 사용해야 합니다.
관련 오류메시지 : REF_CURSOR parameters should be accessed via results
이슈리포트 : https://github.com/spring-projects/spring-data-examples/issues/44
Emp.java
package com.example.employee.model;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.NamedStoredProcedureQueries;
import javax.persistence.NamedStoredProcedureQuery;
import javax.persistence.ParameterMode;
import javax.persistence.StoredProcedureParameter;
import lombok.Data;
@Data
@Entity
@NamedStoredProcedureQueries({
@NamedStoredProcedureQuery(name = "Emp.getEnameByEmpno",
procedureName = "p_getEnameByEmpno",
parameters = {
@StoredProcedureParameter(
mode = ParameterMode.IN, type = Integer.class),
@StoredProcedureParameter(
mode = ParameterMode.OUT, type = String.class) }),
@NamedStoredProcedureQuery(name = "Emp.getEmpByDeptno",
procedureName = "p_getEmpByDeptno",
resultClasses = Emp.class,
parameters = {
@StoredProcedureParameter(
mode = ParameterMode.IN, type = Integer.class),
@StoredProcedureParameter(
mode = ParameterMode.REF_CURSOR, type = void.class) }) })
public class Emp {
@Id
private Integer empno;
private String ename;
private Integer deptno;
}
EmpRepository.java
package com.example.employee.repository;
import java.util.List;
import org.springframework.data.jpa.repository.query.Procedure;
import org.springframework.data.repository.CrudRepository;
import org.springframework.data.repository.query.Param;
import com.example.employee.model.Emp;
public interface EmpRepository extends CrudRepository<Emp, Integer>, EmpRepositoryCustom {
// 사번을 입력받아 이름을 OUT 파라미터로 던지는 프로시저를 호출
@Procedure(name = "Emp.getEnameByEmpno")
String getEnameByEmpno(@Param("p_empno") int p_empno);
// DB에 만든 프로시저 이름을 메소드명으로 사용해서 연동할 수 있다.
// @Procedure
// String p_getEnameByEmpno(Integer p_empno);
@Procedure(name = "Emp.getEmpByDeptno")
List<Emp> getEmpByDeptno(@Param("p_deptno") int p_deptno);
}
EmpRepositoryCustom.java
package com.example.employee.repository;
import java.util.List;
import com.example.employee.model.Emp;
public interface EmpRepositoryCustom {
List<Emp> getEmpByDeptno(int deptno);
}
EmpRepositoryImpl.java
package com.example.employee.repository;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import javax.persistence.StoredProcedureQuery;
import com.example.employee.model.Emp;
public class EmpRepositoryImpl implements EmpRepositoryCustom {
@PersistenceContext
EntityManager em;
@Override
public List<Emp> getEmpByDeptno(int deptno) {
StoredProcedureQuery query = em
.createNamedStoredProcedureQuery("Emp.getEmpByDeptno");
query.setParameter(1, deptno);
query.execute();
@SuppressWarnings("unchecked")
List<Emp> emps = query.getResultList();
return emps;
}
}
EmpRepositoryTest.java
package com.example.employee.repository;
import java.util.List;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.context.SpringBootTest.WebEnvironment;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.transaction.annotation.Transactional;
import com.example.employee.model.Emp;
@Transactional
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
public class EmpRepositoryTest {
@Autowired
private EmpRepository repo;
@Test
public void testGetEmpByDeptno() {
List<Emp> emps = repo.getEmpByDeptno(10);
for (Emp emp : emps) {
System.out.println(emp);
}
}
@Test
public void testGetEnameByEmpno() {
String ename = repo.getEnameByEmpno(7788);
System.out.println("ename = " + ename);
}
}
#Querydsl, #오라클SQL, #JPARownum, #JPAWith문, #Querydsl시퀀스, #JPAUnion, #Querydsl계층쿼리, #Querydsl오라클힌트, #JPA교육, #스프링교육, #자바교육, #Spring교육, #Spring학원, #스프링학원, #자바학원,Querydsl, 오라클SQL, JPARownum, JPAWith문, Querydsl시퀀스, JPAUnion, Querydsl계층쿼리, Querydsl오라클힌트, JPA교육, 스프링교육, 자바교육, Spring교육, Spring학원, 스프링학원, 자바학원



