[동영상]오라클기반 Spring Data JPA, 7.2 Querydsl 실습 Querydsl JPA Query with Oracle,JPA교육,자바학원, 스프링학원, JAVA학원





7.2 Querydsl JPA Query with Oracle, 오라클기반 Spring Data JPA, Querydsl 실습
7.2 Querydsl JPA Query with Oracle
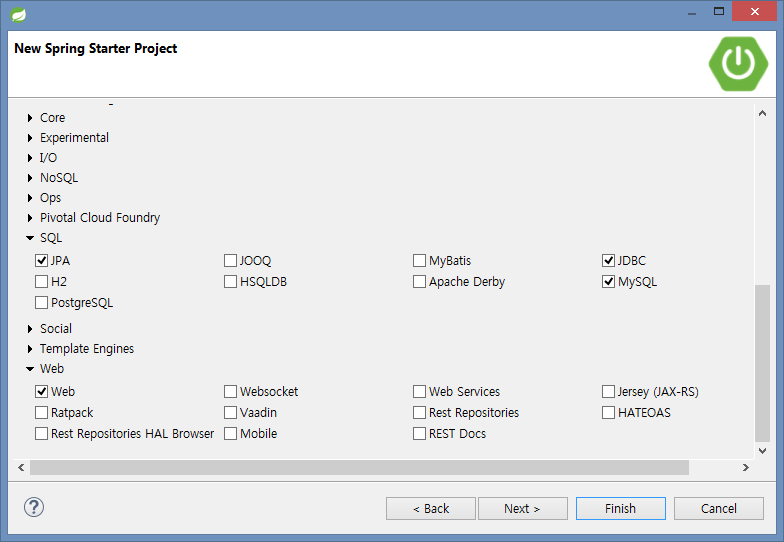
1. 프로젝트 생성
File > New > Spring Starter Project >
프로젝트 명: scaffolding-querydsl-jpa-query-with-oracle > Next >
디펜던시 선택: Lombok, JPA, Web > Finish
2. 오라클 데이터베이스 연결 드라이버 디펜던시 설정 추가
pom.xml
<dependencies>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>oracle</id>
<name>ORACLE JDBC Repository</name>
<url>https://maven.oracle.com;
</repository>
</repositories>
3. 프로젝트 환경 설정
application.properties
# DATASOURCE
spring.datasource.platform=oracle
spring.datasource.sqlScriptEncoding=UTF-8
spring.datasource.url=jdbc:log4jdbc:oracle:thin:@192.168.0.225:1521:orcl
spring.datasource.username=scott
spring.datasource.password=1234
spring.datasource.driver-class-name=net.sf.log4jdbc.sql.jdbcapi.DriverSpy
spring.datasource.initialize=false
# JPA
spring.jpa.hibernate.ddl-auto=none
spring.jpa.database-platform=org.hibernate.dialect.Oracle10gDialect
spring.jpa.show-sql=true
spring.data.jpa.repositories.enabled=true
# Logging
logging.config=classpath:logback-spring.xml
4. 프로젝트 로깅 설정
pom.xml
net.sf.log4jdbc.sql.jdbcapi.DriverSpy 디펜던시 추가
<dependency>
<groupId>org.bgee.log4jdbc-log4j2</groupId>
<artifactId>log4jdbc-log4j2-jdbc4.1</artifactId>
<version>1.16</version>
</dependency>
logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- By default, encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder -->
<encoder>
<pattern>
%d{yyyyMMdd HH:mm:ss.SSS} [%thread] %-3level %logger{5} -%msg %n
</pattern>
</encoder>
</appender>
<logger name="jdbc" level="OFF" />
<logger name="jdbc.sqlonly" level="DEBUG" additivity="false">
<appender-ref ref="STDOUT" />
</logger>
<logger name="jdbc.resultsettable" level="DEBUG" additivity="false">
<appender-ref ref="STDOUT" />
</logger>
<include resource="org/springframework/boot/logging/logback/base.xml"/>
<appender name="dailyRollingFileAppender"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<prudent>true</prudent>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>applicatoin.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<encoder>
<pattern>
%d{yyyy:MM:dd HH:mm:ss.SSS} %-5level --- [%thread] %logger{35} : %msg %n
</pattern>
</encoder>
</appender>
<logger name="org.springframework.web" level="INFO"/>
<logger name="org.thymeleaf" level="INFO"/>
<logger name="org.hibernate.SQL" level="INFO"/>
<logger name="org.quartz.core" level="INFO"/>
<logger name="org.h2.server.web" level="INFO"/>
<root level="INFO">
<appender-ref ref="STDOUT" />
<appender-ref ref="dailyRollingFileAppender" />
</root>
</configuration>
log4jdbc.log4j2.properties
log4jdbc.spylogdelegator.name=net.sf.log4jdbc.log.slf4j.Slf4jSpyLogDelegator
# multi-line query display
log4jdbc.dump.sql.maxlinelength=0
로깅 설정은 부록 7.1과 동일합니다. 다만 나중 편의를 위하여 조금 반복작업을 수행한다고 볼 수 있습니다.
5. 엔티티 클래스 생성
Dept.java
package com.example.employee.model;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.OneToMany;
import com.fasterxml.jackson.annotation.JsonIgnore;
import lombok.Data;
import lombok.ToString;
@Data
@ToString(exclude={"emps"})
@Entity
public class Dept {
@Id
private Long deptno;
@Column(length = 14, nullable = false)
private String dname;
@Column(length = 13)
private String loc;
@OneToMany(mappedBy="dept")
@JsonIgnore
private List<Emp> emps = new ArrayList<Emp>();
public void addEmp(Emp emp){
this.emps.add(emp);
if (emp.getDept() != this) {
emp.setDept(this);
}
}
}
Emp.java
package com.example.employee.model;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.OneToMany;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import com.fasterxml.jackson.annotation.JsonIgnore;
import lombok.Data;
import lombok.ToString;
@Data
@ToString(exclude={"staff"})
@Entity
public class Emp {
@Id
private Long empno;
@Column(length = 10, nullable = false)
private String ename;
@Column(length = 9)
private String job;
@ManyToOne
@JoinColumn(name = "mgr")
private Emp mgr;
@OneToMany(mappedBy = "mgr")
@JsonIgnore
private List<Emp> staff = new ArrayList<Emp>();
@Temporal(TemporalType.DATE)
private Date hiredate;
private Double sal;
private Double comm;
@ManyToOne
@JoinColumn(name = "deptno")
private Dept dept;
public void setDept(Dept dept){
this.dept = dept;
if (!dept.getEmps().contains(this)) {
dept.getEmps().add(this);
}
}
}
엔티티 클래스의 내용은 부록 7.1에서 사용한 엔티티 클래스와 같습니다.
6. Q 타입 클래스 생성을 위한 디펜던시 설정
pom.xml
<dependencies>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>
target/generated-sources/java
</outputDirectory>
<processor>
com.querydsl.apt.jpa.JPAAnnotationProcessor
</processor>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
7. Q 타입 클래스 생성
만약 작업 중 프로젝트에 빨간 x 표시가 보이면 다음 작업을 수행합니다.
프로젝트 선택 > 마우스 오른쪽 클릭 > Maven > Update Project… > 대상 프로젝트 확인 > OK
Q 타입 클래스를 생성하기 위해서 다음 작업을 수행합니다.
프로젝트 선택 > 마우스 오른쪽 클릭 > Run AS > Maven generate-sources
작업결과 프로젝트 구조
프로젝트 선택 > 새로고침 > target/generated-sources/java 폴더 확인
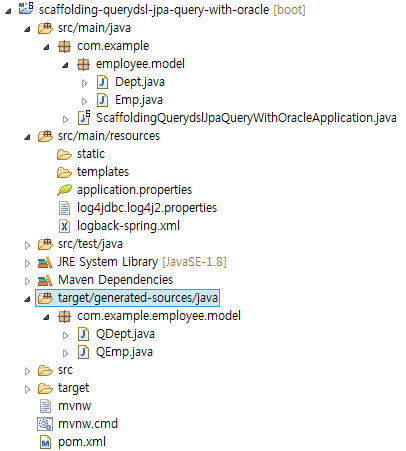
7.1과 7.2는 많은 부분이 비슷합니다. 사실상 다른 부분은 application.properties 뿐인데 이는 Q 타입 클래스 생성 시 사용되지 않으므로 거의 동일하다고 볼 수 있습니다.
연동 데이터베이스가 오라클인 경우 프로젝트 생성 시 오라클 드라이버 디펜던시를 설정할 수 없으므로 별도 수작업으로 pom.xml에 디펜던시를 추가한 부분이 다른 부분입니다.
8. JPAQueryFactory 빈 설정
JPAQueryFactory 를 빈으로 등록해 놓고 필요할 때 DI받아서 사용하면 편리합니다.
QuerydslJpaQueryConfig.java
package com.example.common.config;
import javax.persistence.EntityManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.querydsl.jpa.impl.JPAQueryFactory;
@Configuration
public class QuerydslJpaQueryConfig {
@Bean
public JPAQueryFactory queryFactory(EntityManager em) {
return new JPAQueryFactory(em);
}
}
#JPA오라클, #SpringDataJPA, #Querydsl, #JPA교육,#JPA, #자바동영상, #JPA동영상, JPA오라클, SpringDataJPA, Querydsl, JPA교육,JPA, 자바동영상, JPA동영상,