오라클 INDEX, 오름차순/내림차순 인덱스(Ascending/Descending Index)
인덱스index를 생성 할 때 칼럼명 다음에 ASC 또는 DESC를 기술하지 않으면 기본적으로 오름차순(ASCENDING)으로 인덱스가 생성되는데, 컬럼명 다음에 ASC 라고 기술하면 오름차순, DESC 라고 기술하면 내림차순(DESCENDING)으로 인덱스가 생성됩니다.
오름차순, 내림차순 인덱스 구분은 데이터 조회시 정렬(SORT) 이라는 중요한 기능을 수행 합니다. 인덱스가 내림차순으로 생성되어 있다면 인덱스를 경유하여 데이터를 조회하면 ORDER BY를 기술하지 않더라도 데이터는 내림차순 정렬되어 있을 것 입니다.
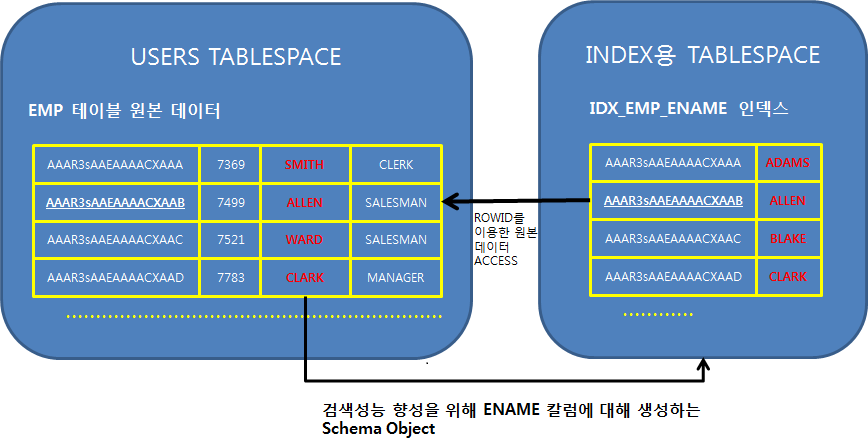
EMP 테이블의 데이터를 조회할 때 SELECT * FROM EMP 이런식으로 인덱스를 경유하지 않고 원본 테이블에서 조회 한다면 출력되는 데이터는 원본 데이터에서 입력된 순서대로 조회됩니다.
만약 전체 사원목록을 조회할 때 사원명으로 내림차순 조회하고 싶다면 대부분 다음처럼 쿼리 할 것 입니다.
SELECT * FROM EMP ORDER BY ENAME;
이때 EMP 테이블의 ename 컬럼에 인덱스가 있고 이를 경유 한다면 원본데이터를 메모리에 올려서 정렬하는 과정을 거치지 않아 다행이지만, 인덱스가 없다면 위 쿼리 구문의 실행을 위해 오라클은 해당 컬럼 값들을 메모리에 올려 정렬sort해야 하므로 대용량 테이블에서는 최악의 쿼리가 될 것 입니다. 실무에서 대용량 테이블인 경우 인덱스가 없는 컬럼에 대해서 절대 이런식으로 사용하시면 안됩니다.
만약 인덱스가 생성되어 있다면 EMP 테이블의 데이터를 추출할 때 인덱스를 경유하도록 하면 데이터는 저절로 정렬되어 있다는 사실을 잘 생각해야 합니다. 이런 경우 일부러 ORDER BY를 사용하지 않아도 인덱스를 경유하도록 하면 데이터는 정렬되어 있을 것 입니다. 이장의 뒷부분에서 실습을 해보겠습니다.
실습에서 오름차순, 내림차순 인덱스를 생성하고 ORDER BY 구문을 사용하지 않아도 인덱스 영역을 경유 하도록 쿼리를 잘 사용하면 데이터는 정렬된다는 것을 실습해 보겠습니다.
실습
오름차순 인덱스를 생성해 보겠습니다.
EMP 테이블의 sal 컬럼에 비고유, 오름차순 인덱스를 생성하세요. |
CREATE INDEX IDX_EMP_SAL ON EMP(SAL ASC);
<실행결과>
Index IDX_EMP_SAL이(가) 생성되었습니다.
컬럼명 다음에 ASC, DESC를 기술하지 않으면 ASC가 기본값 입니다. 위 구문은 다음 구문과 동일 합니다. CREATE INDEX IDX_EMP_SAL ON EMP(SAL)
실습
복합 컬럼에 오름차순, 내림차순 인덱스를 생성해 보겠습니다.
EMP 테이블에서 job 오름차순, sa 내림차순으로 인덱스를 생성 하세요. |
CREATE INDEX IDX_EMP_JOB_SAL ON EMP(JOB, SAL DESC);
<실행결과>
Index IDX_EMP_JOB_SAL이(가) 생성되었습니다.
실습
테이블에 입력되는 순서대로 SELECT 시 조회된다는 사실을 실습을 통해 알아 보겠습니다.
TEST 테이블을 생성 후 3건의 데이터를 입력하고 조회해 보세요. |
CREATE TABLE TEST (
A VARCHAR2(100) PRIMARY KEY,
b VARCHAR2(10));
INSERT INTO TEST VALUES ('1','111');
INSERT INTO TEST VALUES ('3','333');
INSERT INTO TEST VALUES ('2','222');
SELECT * FROM TEST;
<실행결과>
| A | B |
1 | 1 | 111 |
2 | 3 | 333 |
3 | 2 | 222 |
INSERT 문에 의해 입력되는 순서대로 데이터가 조회 됩니다.
실습
ORDER BY 구문을 사용하지 않고도 정렬된 데이터를 추출해 보겠습니다.
현재 EMP 테이블의 ename 컬럼은 인덱스가 생성되어 있습니다.
EMP 테이블의 모든 데이터를 조회하세요. |
SELECT EMPNO, ENAME FROM EMP;
<실행결과>
| EMPNO | ENAME |
1 | 7369 | SMITH |
... | ... | ... |
13 | 7902 | FORD |
14 | 7934 | MILLER |
EMP 테이블에 입력된 순서대로 조회 됩니다.
EMP 테이블에서 모든 사원의 empno, ename 컬럼 데이터를 조회하세요.(단 ename 오름차순으로 정렬) |
SELECT EMPNO, ENAME FROM EMP ORDER BY ENAME;
<실행결과>
| EMPNO | ENAME |
1 | 7876 | ADAMS |
... | ... | ... |
13 | 7844 | TURNER |
14 | 7521 | WARD |
ename 컬럼을 기준으로 오름차순 정렬되어 조회 됩니다.
이번에는 ORDER BY 구문을 이용하지 않고 인덱스를 경유하도록 해서 데이터를 조회해 보겠습니다.
EMP 테이블에서 모든 사원의 empno, ename 컬럼 데이터를 조회하세요.(단 ename 오름차순으로 정렬) |
SELECT EMPNO, ENAME FROM EMP WHERE ENAME > 'A';
<실행결과>
| EMPNO | ENAME |
1 | 7876 | ADAMS |
... | ... | ... |
13 | 7844 | TURNER |
14 | 7521 | WARD |
ename 컬럼을 기준으로 오름차순 정렬되어 조회 됩니다.
ORDER BY를 사용하지 않았지만 오라클을 감동시켜 ename 인덱스를 경유 하도록 하기 위해 WHERE 절에 ename 컬럼을 일부러 출현시켰더니 오라클이 ename 인덱스를 경유하여 오름차순으로 데이터가 조회 되었습니다. 여기서 우리는 WHERE 절에 인덱스 컬럼을 출현시키면 오라클이 해당 컬럼의 인덱스 영역에서 데이터를 조회한다는 사실을 알았습니다.
사실 중요한 것은 ORDER BY를 사용했냐 안했냐가 아니라 내가 작성한 쿼리문이 적절한 인덱스를 경유하여 검색 속도에 문제가 없는지 입니다.
ORDER BY는 인덱스가 없는 컬럼에 대해 사용하게 되면 100% 메모리에 올려 정렬이라는 과정을 거치게 되어 있으므로 대용량 테이블인 경우 조회 속도는 최악 입니다. 정말 주의 해야 합니다.
물론 ORDER BY를 사용하더라도 컬럼에 인덱스가 있다면 원본 데이터를 정렬하는 것보다 대체로 인덱스 영역에서 데이터를 가지고 오니 큰 무리는 없습니다. 그러므로 ORDER BY를 사용했다면 오라클의 실행계획execution plan(SQL Developer에서 F12)을 반드시 확인하여 ORDER BY에 사용한 컬럼의 인덱스를 경유하는 지를 반드시 확인해야 합니다.
오라클에서 쿼리 실행전 중요한 구성요소중 하나는 오라클 옵티마이저oracle optimizer 입니다. 옵티마이저는 다양한 실행 경로를 생성하고 비용(COST)이 가장 적게드는 최적의 실행경로를 선택합니다.
실행계획은 오라클 옵티마이저(Oracle Optimizer)가 SQL문장의 실행을 위해 테이블의 데이터를 원본에서 하나씩 읽어서 접근할 것인지, 어떤 인덱스에서 랜덤 액세스를 통해 접근할 것인지, 어떤 SQL연산을 사용할 것인지, 어떤 조인순서로 조인을 하고, 어떤 조인을 사용할 것인지 등에 대해 계획을 수립한 것 입니다.
실습
이번에는 ename 컬럼의 인덱스를 내림차순으로 생성한 후 ename 내림차순으로 데이터를 조회해 보겠습니다.
ename 컬럼에 생성되어 있는 IDX_EMP_ENAME 인덱스를 삭제하고 내림차순 인덱스를 다시 생성하세요. |
DROP INDEX IDX_EMP_NAME;
CREATE INDEX IDX_EMP_ENAME ON EMP(ENAME DESC);
EMP 테이블에서 모든 사원의 empno, ename 컬럼 데이터를 조회하세요.(단 ename 내림차순으로 정렬) |
SELECT EMPNO, ENAME FROM EMP ORDER BY ENAME DESC;
<실행결과>
| EMPNO | ENAME |
1 | 7521 | WARD |
... | ... | ... |
13 | 7499 | ALLEN |
14 | 7876 | ADAMS |
ename 컬럼을 기준으로 내림차순 정렬되어 있습니다.
이번에는 ORDER BY 구문을 이용하지 않고 인덱스를 경유하도록 해서 데이터를 조회해 보겠습니다.
EMP 테이블에서 모든 사원의 empno, ename 컬럼 데이터를 조회하세요.(단 ename 내림차순으로 정렬) |
SELECT EMPNO, ENAME FROM EMP WHERE ENAME > 'A';
<실행결과>
| EMPNO | ENAME |
1 | 7521 | WARD |
... | ... | ... |
13 | 7499 | ALLEN |
14 | 7876 | ADAMS |
ORDER BY를 사용하지 않았지만 WHERE절에 ename 컬럼을 출현시켜 오라클에게 ename 컬럼 인덱스를 경유하여 데이터를 추출하도록 했습니다. WHERE절에 컬럼을 출현시키는 방법이외에 오라클의 힌트 구문을 이용하여 원하는 인덱스를 경유하여 데이터를 추출하도록 할 수 있습니다.
#인덱스, #오름차순인덱스, #INDEX, #오라클인덱스, #오라클, #오라클강좌, #오라클교육, #ORACLE