Spring Data JPA소개 및 Simple 예제 실습, JPA란? HelloWorld,자바학원/SQL학원/자바교육/SQL교육/JAVA학원/JAVA교육,자바동영상
https://www.youtube.com/watch?v=RdIPh1iGm5A&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=7

https://www.youtube.com/watch?v=rwDOqrM2B9Q&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=2

https://www.youtube.com/watch?v=pue8iaffaXM&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=3

https://www.youtube.com/watch?v=w6XoZ3Luzus&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=4

https://www.youtube.com/watch?v=2Ct32nlhBzA&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=1

http://ojc.asia/bbs/board.php?bo_table=LecJpa&wr_id=361
ojc.asia
https://www.youtube.com/watch?v=Xb0OEOiZ3Rg&list=PLxU-iZCqT52AlV-Y7UlwSQp8N6pMjijFX&index=6

Spring Data JPA
JPA는 ORM 기술의 자바진영 표준 스펙입니다. JPA의 실현체로는 Hibernate가 가장 널리 사용되고 있습니다. 유료버전을 제외한다면 사실 상 쓸만한 기술로는 Hibernate 뿐이라고 할 수 있습니다. 그러므로 일반적으로 JPA를 사용해서 개발한다고 말할 때는 Hibernate를 사용하여 데이터베이스 연동로직을 처리한다고 볼 수 있습니다.
Hibernate는 스프링 없이 단독으로 사용할 수 있는 기술입니다. 하지만 대부분의 경우 스프링 기반에서 Hibernate를 연동해서 사용합니다. 이는 스프링의 기반 기술인 IoC, AOP, PSA의 장점을 이용하고 싶기 때문입니다. 더불어 스프링이 JPA를 보다 편리하게 사용할 수 있도록 서포트하는 기술인 Spring Data JPA 기술은 Hibernate를 스프링 기반에서 사용해야 하는 강력한 이유가 됩니다. 스프링이 제공하는 기술을 사용하면 반복적이고 뻔한 로직은 더 이상 개발자가 작성할 필요가 없고 스프링이 Hibernate와 협력하여 개발자 대신 처리 해 줍니다.
마이바티스와 JPA의 가장 큰 차이점은 다음과 같습니다. 마이바티스를 사용했을 때는 개발자가 SQL 쿼리를 직접 작성해서 알려주어야 하지만 Spring Data JPA를 사용하면 SQL 쿼리는 JPA의 구현체인 Hibernate가 작성해서 사용합니다. 마이바티스가 인터페이스의 구현체를 개발자 대신 만들어서 제공하는 기능을 스프링 역시 Spring Data JPA 기술을 사용하여 선보였습니다. 개발자를 대신해서 쿼리는 Hibernate가, 인터페이스 구현체는 스프링이 처리함으로서 개발자는 반복되는 뻔한 DAO 로직에서 점점 더 해방되어 가고 있습니다.
Spring Data JPA 기술은 마이바티스보다 한 발 더 나아가서 스프링이 제안하는 인터페이스를 상속하기만 하면 스프링이 인터페이스에 미리 정의해 놓은 메소드들을 개발자의 DAO 인터페이스 구현체를 생성하면서 그 안에 넣어 주는 서비스를 제공합니다.
스프링은 JDBC 기술을 보다 쉽게 사용하도록 Spring JDBC로 업그레이드 해서 제공하고 있는 것을 앞서 살펴 보았습니다. 프로젝트 관리성 측면을 고려한다면 JDBC를 업그레이드한 기술인 마이바티스를 선택할 수도 있었습니다. 이러한 데이터베이스 처리 기술들은 공통적으로 개발자가 직접 SQL 쿼리를 작성해야 합니다.
그런데 SQL 쿼리는 데이터베이스마다 조금씩 달라서 만약 데이터베이스가 변경되어야 하는 큰 환경적인 변화가 있다면 쿼리들을 모두 개발자가 작성해서 사용하는 경우 큰 난관 봉착하는데 개발자가 직접 모든 쿼리를 수작업으로 변경해야만 하기 때문입니다.. 그래서 개발자들은 데이터베이스가 바뀔 때마다 개발자가 직접 쿼리를 수정하지 않고도 처리할 수 있는 방법을 찾게 되었습니다.
객체로 테이블을 관리하는 ORM의 역사가 이렇게 시작되었습니다. 어찌보면 자바측에서는 Hibernate의 역사가 곧 ORM의 역사라고 할 수 있습니다. Hibernate의 설립자인 개빈 킹(Gavin King)이 JPA 스펙의 근간을 설계했습니다.
ORM에 대한 이해를 돕기 위해서 예를 들어 보면 우리는 외국인과 대화하기 위해서 해당 국가의 언어를 직접 배운 후 대화해야 합니다. 그런데 만약 통역사를 고용할 수만 있다면 직접 외국어를 배우지 않고도 통역사를 통해서 대화할 수 있게 됩니다. 이는 통역사가 중간에서 번역 서비스를 제공하기 때문에 가능한 일입니다. 다국어를 구사하는 능력 있는 통역사만 있다면 우리가 사용해야 하는 외국어가 계속 늘어나도 전혀 걱정이 없습니다.
이 개념을 데이터베이스 처리기술에 도입한 것이 ORM기술입니다.
JPA의 EntityManager가 모델 객체와 데이터베이스 중간에 개입하여 SQL쿼리를 대신 작성하여 질의하고 결과를 돌려줍니다. 따라서 개발자는 직접 질의하는 SQL을 사용하지 않고 EntityManager에게 요청하기 위해서 SQL대신 JPA가 이해하는 JPQL을 사용합니다. SQL은 데이터베이스의 방언에 따라 바꿔서 사용해야 하지만 JPQL은 바뀌지 않습니다. 바로 우리가 통역사에게 한국어(JPQL)로만 얘기해도 괜찮은 것과 비슷합니다. 여러 외국어(SQL)로 바꿔서 처리하는 것은 통역사(EntityManager)의 몫 입니다.
EntityManager는 모델 클래스를 기반으로 데이터베이스와의 질의 및 결과처리를 수행합니다. 따라서 개발자는 모델 클래스와 관련된 테이블 스키마 정보를 설정해야 합니다. 이를 설정하는 방법은 XML과 어노테이션 방식이 있습니다. JPA에서는 어노테이션으로 설정하는 방식을 선호합니다. JPA를 사용한다면 개발자는 모델 객체를 조작해서 테이블 처리작업을 수행할 수 있습니다. 이는 마치 JPA라는 다국어에 능통한 통역사를 고용한 것과 같습니다.
쿼리를 처리하는 JPA 통역사는 스마트해서 반복적인 질의를 하게 되는 경우 매번 데이터베이스에 질의하는 행동을 하지 않습니다. JPA는 Persistence Context를 사용하여 데이터를 담고 있는 모델객체들을 보관합니다. 개발자가 모델클래스를 사용해서 JPQL로 EntityManager에게 질의하면, Persistence Context 내에 요청 받은 데이터를 갖고 있는 객체가 있는지 살펴보고 있다면 데이터베이스에 질의하지 않고 바로 갖고 있는 모델객체의 복사본을 만들어 돌려줍니다. 이러한 기능을 기존에 사용하던 ehcache 캐싱서비스 등과 구분하기 위해서 1차 캐싱 기능이라고 부릅니다.
간단하게 스프링 기반에서 JPA를 사용하는 방법을 살펴보겠습니다.
새 프로젝트 생성
File > New > Spring Starter Project >
프로젝트 명: chapter1-4 > Next >
디펜던시 선택: Web, JDBC, MySQL, JPA > Finish
JDBC 디펜던시는 선택하지 않아도 됩니다.
프로젝트 환경설정
application.properties
# DATASOURCE
spring.datasource.platform=mariadb
spring.datasource.sqlScriptEncoding=UTF-8
spring.datasource.url=jdbc:mysql://localhost:3306/testdb?createDatabaseIfNotExist=true
spring.datasource.username=root
spring.datasource.password=1111
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# JPA
spring.jpa.hibernate.ddl-auto=create
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql=true
spring.data.jpa.repositories.enabled=true
spring.jpa.hibernate.ddl-auto=create
프로젝트 기동 시 엔티티 클래스를 바탕으로 테이블을 생성합니다. 만약 테이블이 이미 존재한다면 삭제하고 다시 생성합니다.
- create-drop : create설정 + 프로젝트 중지 시 생성한 테이블을 삭제합니다.
- none : 아무것도 하지 않습니다.
- update : 엔티티와 테이블을 비교하여 일치하지 않는 부분만 처리합니다.
- validate : 엔티티와 테이블을 비교하여 일치하지 않으면 예외를 발생시킵니다.
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
Maria DB는 MySQL 계열에 데이터베이스로써 MySQL5InnoDBDialect 방언을 지정합니다. 별도의 Maria DB 전용 지정 문자열은 존재하지 않습니다.
spring.jpa.show-sql=true
JPA가 생성하여 사용하는 SQL 쿼리를 로그에 출력합니다. 엔티티매니저가 SQL 쿼리를 적합하게 사용하는지 확인할 필요가 있기 때문에 개발중에는 true로 설정합니다.
spring.data.jpa.repositories.enabled=true
Spring Data JPA가 제안하는 인터페이스를 상속한 클래스가 있으니 처리하라고 요청합니다.
스캐폴딩
다음 그림을 보고 패키지 및 폴더를 생성합니다. com.example.employee 패키지 밑으로 하부 패키지 및 클래스 파일들을 생성합니다.
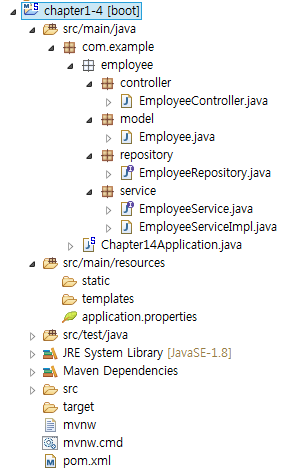
모델 클래스
JPA 기술을 사용하면 모델클래스 정의가 곧 테이블 정의가 됩니다. @Entity 어노테이션은 JPA에게 이 클래스에 테이블 정의 정보가 있다고 알려줍니다.
Employee.java
package com.example.employee.model;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Employee {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
private Long empno;
private String ename;
private String job;
public Employee() {}
public Employee(Long empno, String ename, String job) {
this.empno = empno;
this.ename = ename;
this.job = job;
}
// getter, setter 생략
}
테이블명 설정을 위한 @Table(name="employee") 어노테이션을 지정하지 않으면 클래스이름을 테이블명으로 사용합니다. 칼럼 설정을 위한 @Column(name="ename") 어노테이션을 지정하지 않으면 필드변수 이름을 칼럼명으로 사용하고 필드변수의 자료형을 취급할 수 있는 칼럼자료형을 환경설정으로 알려 준 데이터베이스에 맞게 자동으로 선택합니다.
전통적인 개발 순서는 먼저 업무분석을 통해 논리 모델을 만들고 데이터베이스에 따라 물리 모델을 만듭니다. 따라서 완성된 ERD가 존재하게 되며 테이블들은 모두 정의서가 있는 상태가 됩니다. 테이블 정의에 따라 개발자는 모델 클래스를 생성하고 다음으로 DAO 로직 클래스를 생성하는 순서로 개발이 진행됩니다.
JPA 기술을 사용하면 전통적인 bottom-up 개발방식의 순서를 따르지 않게 됩니다. JPA 기술을 사용하면 논리모델을 만드는 순서까지는 같지만 물리모델을 만들기 전에 모델 클래스를 생성합니다. 모델 클래스에 정의한 내용을 바탕으로 JPA가 DB에 접속하여 테이블을 생성합니다. 물리모델 ERD를 얻고 싶다면 리버스 엔지니어링을 통해 얻을 수 있습니다.
JPA를 사용한다고 해서 전통적인 개발순서를 따르지 못하는 것은 아닙니다. 이미 물리모델이 존재하는 경우 이를 바탕으로 엔티티 클래스들을 얻을 수 있습니다. 대표적인 기술로써 JBoss가 제공하는 Hibernate Tools가 있습니다. JPA를 사용하지 않고 개발된 기존 프로젝트에 JPA 기술을 도입하는 경우 이 방법이 적합할 것입니다.
자세한 사용법은 다음 사이트를 참고하세요.
Persistence Layer
Spring Data JPA 기술을 사용할 때 가장 큰 변화가 있는 부분은 DAO 로직을 정의하는 클래스입니다. 스프링이 제안하는 인터페이스 JpaRepository를 상속하면 부모 인터페이스들에 정의된 추상메소드들의 유효범위를 연장한 것이므로 개발자가 이런 용도의 추상메소드들을 정의할 필요가 없습니다.
EmployeeRepository.java
package com.example.employee.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import com.example.employee.model.Employee;
public interface EmployeeRepository extends JpaRepository<Employee, Long>{
// nothing
}
<Employee, Long>
첫 번째 제네릭으로 모델 클래스를 지정하고 두 번째 제네릭으로 모델 클래스 안에 키 역할을 수행하는 필드변수의 자료형을 지정합니다. @Entity가 붙어 있는 클래스가 곧 테이블 스키마라고 볼 수 있으므로 @Id가 붙어 있는 필드변수가 곧 Primary Key가 됩니다. 엔티티매니저는 제네릭으로 객체형을 요구합니다. 그에 따라 필드변수 자료형을 Wrapper클래스 자료형인 Long으로 선언합니다.
// nothing
스프링이 제공하는 기본적인 CRUD 메소드들만 필요하다면 추가로 개발자가 해야 할 작업은 없습니다. 개발자의 판단에 따라 메소드들이 더 필요하다면 추가로 정의할 수 있습니다. 이 경우 정의 된 메소드가 사용할 쿼리를 개발자가 알려줄 필요가 있습니다. 이러한 경우를 염두에 두고 스프링은 스프링이 제안하는 메소드 작성법을 따르다면 메소드가 사용해야 하는 쿼리를 별도로 알려주지 않아도 되는 기술을 제공합니다. 이를 쿼리 메소드라고 부릅니다. 뒤에서 살펴보겠습니다.
EmployeeRepository extends JpaRepository
스프링은 JpaRepository 인터페이스에서부터 부모 인터페이스들에 정의되어 있는 모든 메소드들을 EmployeeRepository 인터페이스 구현체를 만들면서 추가합니다. 모든 메소드가 필요하지는 않고 몇 개의CRUD 메소드만 필요하다면 JpaRepository 인터페이스의 부모 인터페이스들 중 하나를 바로 상속하여 사용하는 것이 좋습니다.

위 그림을 보면 프리젠테이션 레이어에서 데이터를 표시할 때 처리해야 하는 대표기능 중에 하나인 Paging 로직을 위한 findAll(Pageable) 메소드가 포함되어 있다는 것을 알 수 있습니다. 페이징 처리 코드는 뒤에서 살펴보도록 하겠습니다.
application.properties 설정파일에서 spring.data.jpa.repositories.enabled=true라고 설정했기 때문에 클래스 위에 @Repository 어노테이션은 붙일 필요가 없습니다.
Service Layer
DAO 클래스의 메소드들을 개발자가 직접 정의하지 않고 스프링이 제안하는 메소드들을 그대로 사용함으로써 메소드명은 고정이 됩니다. 대신 개발자는 서비스 레이어에서 자신의 스타일에 맞게 메소드들을 정의해서 사용하면 됩니다.
EmployeeService.java
package com.example.employee.service;
import java.util.List;
import com.example.employee.model.Employee;
public interface EmployeeService {
public List<Employee> select();
}
EmployeeServiceImpl.java
package com.example.employee.service;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.example.employee.model.Employee;
import com.example.employee.repository.EmployeeRepository;
@Service
public class EmployeeServiceImpl implements EmployeeService {
@Autowired
private EmployeeRepository employeeRepository;
@Override
public List<Employee> select() {
return employeeRepository.findAll();
}
}
Persistence Layer
EmployeeController.java
package com.example.employee.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import com.example.employee.service.EmployeeService;
@RestController
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@GetMapping("/employees")
public Object getEmployees(){
return employeeService.select();
}
}
테스트
무엇을 테스트해야 하는지 생각해 봅니다.
@Entity가 붙어 있는 모델클래스를 바탕으로 데이터베이스에 테이블이 생성되는지 여부
application.properties 설정파일에 spring.jpa.hibernate.ddl-auto=create로 설정했으므로 기존 테이블이 있다면 삭제하고 새로 테이블을 만들어야 합니다. "create" 대신 "update"를 지정하면 변화가 있을 때만 테이블을 새로 생성합니다. "update"로 설정해서 사용하는 경우 주의할 점은 엔티티 클래스에서 필드변수명을 바꾸는 경우 테이블에 칼럼이 추가되기만 할 뿐 기존 칼럼은 삭제되지 않는다는 점 입니다. 더 이상 사용하지 않는 칼럼을 삭제하기 위해서는 테이블을 새로 만들어야 가능하므로 "create" 옵션으로 설정해야 합니다.
새로 테이블을 생성한다면 데이터가 없는 빈 테이블이므로 조회 테스트를 수행해도 결과를 얻을 수 없습니다. 조회 테스트를 위해서 더미 데이터를 미리 입력해 놓고 사용하고 싶습니다. 스프링 부트는 다음 파일을 프로젝트 기동 시 처리해 주므로 이러한 작업에 적합합니다. data.sql 파일을 프로젝트에 추가합니다.
data.sql
파일 위치: src/main/resources/data.sql
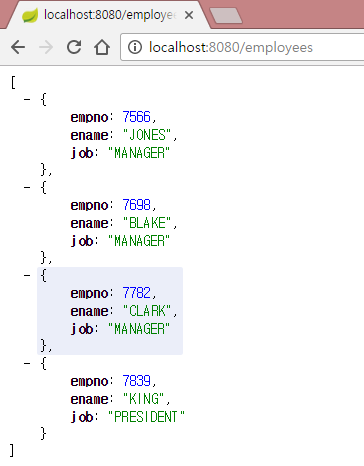
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7839,'KING','PRESIDENT');
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7566,'JONES','MANAGER');
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7698,'BLAKE','MANAGER');
INSERT IGNORE INTO EMPLOYEE(empno, ename, job) VALUES(7782,'CLARK','MANAGER');
IGNORE 옵션을 사용하기 때문에 매번 프로젝트를 기동해도 키 중복 예외는 발생하지 않을 것입니다.
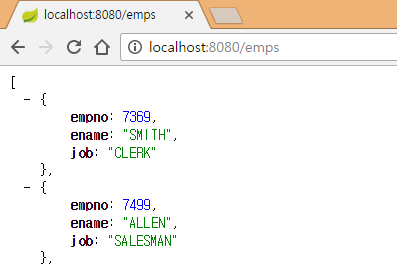
http://localhost:8080/employees 주소로 서버에 접근해서 결과를 확인합니다.
정리
SQL 쿼리를 개발자가 만들지 않아도 되는 기술의 가장 큰 혜택을 받는 분야는 솔루션을 만들어 서비스하는 분야일 것입니다. 기존에는 클라이언트가 사용하는 다양한 데이터베이스를 지원하기 위해서 매번 해당 데이터베이스에 맞게 DAO로직 클래스를 만들어야 했지만 이제 더 이상 그럴 필요가 없습니다. Hibernate는 약 40개 이상의 데이터베이스 방언을 지원하고 있습니다.
네트워크가 발전함에 따라 분산환경에서의 기술이 발전하고 있습니다. 예로 소프트웨어는 본사 서버에서 제공하고 데이터베이스는 각 지사의 데이터베이스를 이용하는 상황을 들 수 있습니다. 이 경우에 하나의 소프트웨어가 다수의 데이터베이스를 처리할 수 있어야 하므로 JPA가 훌륭한 해결책이 됩니다. 더불어서 소프트웨어의 빈번한 업데이트가 있는 경우 관리적인 측면을 고려한다면 더욱 더 JPA의 기술이 매력적으로 느껴질 것입니다.
JPA를 스프링이 서포트 하는 기술인 Spring Data JPA를 사용하면 이제 개발자는 DAO 인터페이스에 추상메소드들을 정의하는 작업도 필요 없게 되었습니다. 기본적인 CRUD 메소드는 스프링이 정의한 인터페이스를 상속하는 걸로 스프링이 미리 정의해 놓은 메소드들을 이용할 수 있습니다.
그러나 많은 경우 스프링이 제안하는 추상 메소드들 외에 메소드들이 필요합니다. 개발자가 추가하는 메소드들도 스프링은 최대한 자동적으로 처리되도록 해 주는 서비스를 제공합니다.